Cell type annotation
Last updated on 2024-11-11 | Edit this page
Estimated time: 45 minutes
Overview
Questions
- How can we identify groups of cells with similar expression profiles?
- How can we identify genes that drive separation between these groups of cells?
- How to leverage reference datasets and known marker genes for the cell type annotation of new datasets?
Objectives
- Identify groups of cells by clustering cells based on gene expression patterns.
- Identify marker genes through testing for differential expression between clusters.
- Annotate cell types through annotation transfer from reference datasets.
- Annotate cell types through marker gene set enrichment testing.
Setup
Again we’ll start by loading the libraries we’ll be using:
R
library(AUCell)
library(MouseGastrulationData)
library(SingleR)
library(bluster)
library(scater)
library(scran)
library(pheatmap)
library(GSEABase)
Data retrieval
We’ll be using the fifth processed sample from the WT chimeric mouse embryo data:
R
sce <- WTChimeraData(samples = 5, type = "processed")
sce
OUTPUT
class: SingleCellExperiment
dim: 29453 2411
metadata(0):
assays(1): counts
rownames(29453): ENSMUSG00000051951 ENSMUSG00000089699 ...
ENSMUSG00000095742 tomato-td
rowData names(2): ENSEMBL SYMBOL
colnames(2411): cell_9769 cell_9770 ... cell_12178 cell_12179
colData names(11): cell barcode ... doub.density sizeFactor
reducedDimNames(2): pca.corrected.E7.5 pca.corrected.E8.5
mainExpName: NULL
altExpNames(0):To speed up the computations, we take a random subset of 1,000 cells.
R
set.seed(123)
ind <- sample(ncol(sce), 1000)
sce <- sce[,ind]
Preprocessing
The SCE object needs to contain log-normalized expression counts as well as PCA coordinates in the reduced dimensions, so we compute those here:
R
sce <- logNormCounts(sce)
sce <- runPCA(sce)
Clustering
Clustering is an unsupervised learning procedure that is used to empirically define groups of cells with similar expression profiles. Its primary purpose is to summarize complex scRNA-seq data into a digestible format for human interpretation. This allows us to describe population heterogeneity in terms of discrete labels that are easily understood, rather than attempting to comprehend the high-dimensional manifold on which the cells truly reside. After annotation based on marker genes, the clusters can be treated as proxies for more abstract biological concepts such as cell types or states.
Graph-based clustering is a flexible and scalable technique for identifying coherent groups of cells in large scRNA-seq datasets. We first build a graph where each node is a cell that is connected to its nearest neighbors in the high-dimensional space. Edges are weighted based on the similarity between the cells involved, with higher weight given to cells that are more closely related. We then apply algorithms to identify “communities” of cells that are more connected to cells in the same community than they are to cells of different communities. Each community represents a cluster that we can use for downstream interpretation.
Here, we use the clusterCells() function from the scran package to
perform graph-based clustering using the Louvain
algorithm for community detection. All calculations are performed
using the top PCs to take advantage of data compression and denoising.
This function returns a vector containing cluster assignments for each
cell in our SingleCellExperiment object. We use the
colLabels() function to assign the cluster labels as a
factor in the column data.
R
colLabels(sce) <- clusterCells(sce, use.dimred = "PCA",
BLUSPARAM = NNGraphParam(cluster.fun = "louvain"))
table(colLabels(sce))
OUTPUT
1 2 3 4 5 6 7 8 9 10 11
100 160 99 141 63 93 60 108 44 91 41 You can see we ended up with 11 clusters of varying sizes.
We can now overlay the cluster labels as color on a UMAP plot:
R
sce <- runUMAP(sce, dimred = "PCA")
plotReducedDim(sce, "UMAP", color_by = "label")
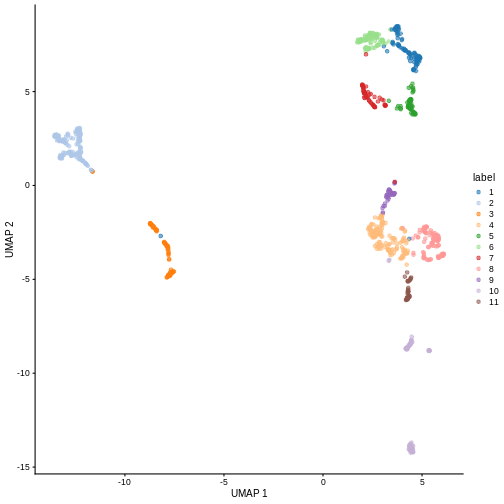
Challenge
Our clusters look semi-reasonable, but what if we wanted to make them
less granular? Look at the help documentation for
?clusterCells and ?NNGraphParam to find out
what we’d need to change to get fewer, larger clusters.
We see in the help documentation for ?clusterCells that
all of the clustering algorithm details are handled through the
BLUSPARAM argument, which needs to provide a
BlusterParam object (of which NNGraphParam is
a sub-class). Each type of clustering algorithm will have some sort of
hyper-parameter that controls the granularity of the output clusters.
Looking at ?NNGraphParam specifically, we see an argument
called k which is described as “An integer scalar
specifying the number of nearest neighbors to consider during graph
construction.” If the clustering process has to connect larger sets of
neighbors, the graph will tend to be cut into larger groups, resulting
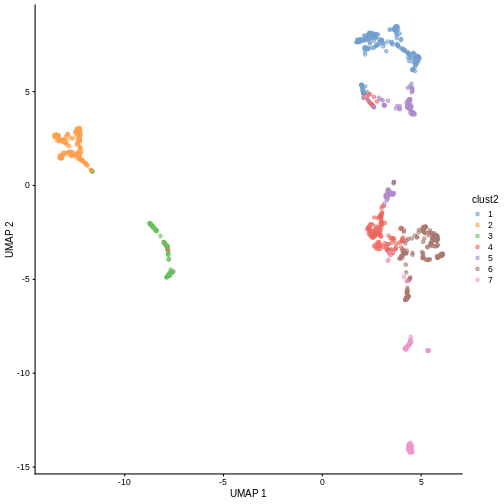
in less granular clusters. Try the two code blocks above once more with
k = 30. Given their visual differences, do you think one
set of clusters is “right” and the other is “wrong”?
R
sce$clust2 <- clusterCells(sce, use.dimred = "PCA",
BLUSPARAM = NNGraphParam(cluster.fun = "louvain",
k = 30))
plotReducedDim(sce, "UMAP", color_by = "clust2")
Marker gene detection
To interpret clustering results as obtained in the previous section, we identify the genes that drive separation between clusters. These marker genes allow us to assign biological meaning to each cluster based on their functional annotation. In the simplest case, we have a priori knowledge of the marker genes associated with particular cell types, allowing us to treat the clustering as a proxy for cell type identity.
The most straightforward approach to marker gene detection involves testing for differential expression between clusters. If a gene is strongly DE between clusters, it is likely to have driven the separation of cells in the clustering algorithm.
Here, we use scoreMarkers() to perform pairwise
comparisons of gene expression, focusing on up-regulated (positive)
markers in one cluster when compared to another cluster.
R
rownames(sce) <- rowData(sce)$SYMBOL
markers <- scoreMarkers(sce)
markers
OUTPUT
List of length 11
names(11): 1 2 3 4 5 6 7 8 9 10 11The resulting object contains a sorted marker gene list for each cluster, in which the top genes are those that contribute the most to the separation of that cluster from all other clusters.
Here, we inspect the ranked marker gene list for the first cluster.
R
markers[[1]]
OUTPUT
DataFrame with 29453 rows and 19 columns
self.average other.average self.detected other.detected
<numeric> <numeric> <numeric> <numeric>
Xkr4 0.0000000 0.00366101 0.00 0.00373784
Gm1992 0.0000000 0.00000000 0.00 0.00000000
Gm37381 0.0000000 0.00000000 0.00 0.00000000
Rp1 0.0000000 0.00000000 0.00 0.00000000
Sox17 0.0279547 0.18822927 0.02 0.09348375
... ... ... ... ...
AC149090.1 0.3852624 0.352021067 0.33 0.2844935
DHRSX 0.4108022 0.491424091 0.35 0.3882325
Vmn2r122 0.0000000 0.000000000 0.00 0.0000000
CAAA01147332.1 0.0164546 0.000802687 0.01 0.0010989
tomato-td 0.6341678 0.624350570 0.51 0.4808379
mean.logFC.cohen min.logFC.cohen median.logFC.cohen
<numeric> <numeric> <numeric>
Xkr4 -0.0386672 -0.208498 0.0000000
Gm1992 0.0000000 0.000000 0.0000000
Gm37381 0.0000000 0.000000 0.0000000
Rp1 0.0000000 0.000000 0.0000000
Sox17 -0.1383820 -1.292067 0.0324795
... ... ... ...
AC149090.1 0.0644403 -0.1263241 0.0366957
DHRSX -0.1154163 -0.4619613 -0.1202781
Vmn2r122 0.0000000 0.0000000 0.0000000
CAAA01147332.1 0.1338463 0.0656709 0.1414214
tomato-td 0.0220121 -0.2535145 0.0196130
max.logFC.cohen rank.logFC.cohen mean.AUC min.AUC median.AUC
<numeric> <integer> <numeric> <numeric> <numeric>
Xkr4 0.000000 6949 0.498131 0.489247 0.500000
Gm1992 0.000000 6554 0.500000 0.500000 0.500000
Gm37381 0.000000 6554 0.500000 0.500000 0.500000
Rp1 0.000000 6554 0.500000 0.500000 0.500000
Sox17 0.200319 1482 0.462912 0.228889 0.499575
... ... ... ... ... ...
AC149090.1 0.427051 1685 0.518060 0.475000 0.508779
DHRSX 0.130189 3431 0.474750 0.389878 0.471319
Vmn2r122 0.000000 6554 0.500000 0.500000 0.500000
CAAA01147332.1 0.141421 2438 0.504456 0.499560 0.505000
tomato-td 0.318068 2675 0.502868 0.427083 0.501668
max.AUC rank.AUC mean.logFC.detected min.logFC.detected
<numeric> <integer> <numeric> <numeric>
Xkr4 0.50 6882 -2.58496e-01 -1.58496e+00
Gm1992 0.50 6513 -8.00857e-17 -3.20343e-16
Gm37381 0.50 6513 -8.00857e-17 -3.20343e-16
Rp1 0.50 6513 -8.00857e-17 -3.20343e-16
Sox17 0.51 3957 -4.48729e-01 -4.23204e+00
... ... ... ... ...
AC149090.1 0.588462 1932 2.34565e-01 -4.59278e-02
DHRSX 0.530054 2050 -1.27333e-01 -4.52151e-01
Vmn2r122 0.500000 6513 -8.00857e-17 -3.20343e-16
CAAA01147332.1 0.505000 4893 7.27965e-01 -6.64274e-02
tomato-td 0.576875 1840 9.80090e-02 -2.20670e-01
median.logFC.detected max.logFC.detected rank.logFC.detected
<numeric> <numeric> <integer>
Xkr4 0.00000000 3.20343e-16 5560
Gm1992 0.00000000 3.20343e-16 5560
Gm37381 0.00000000 3.20343e-16 5560
Rp1 0.00000000 3.20343e-16 5560
Sox17 -0.00810194 1.51602e+00 341
... ... ... ...
AC149090.1 0.0821121 9.55592e-01 2039
DHRSX -0.1774204 2.28269e-01 3943
Vmn2r122 0.0000000 3.20343e-16 5560
CAAA01147332.1 0.8267364 1.00000e+00 898
tomato-td 0.0805999 4.63438e-01 3705Each column contains summary statistics for each gene in the given
cluster. These are usually the mean/median/min/max of statistics like
Cohen’s d and AUC when comparing this cluster (cluster 1 in
this case) to all other clusters. mean.AUC is usually the
most important to check. AUC is the probability that a randomly selected
cell in cluster A has a greater expression of gene X
than a randomly selected cell in cluster B. You can set
full.stats=TRUE if you’d like the marker data frames to
retain list columns containing each statistic for each pairwise
comparison.
We can then inspect the top marker genes for the first cluster using
the plotExpression function from the scater package.
R
c1_markers <- markers[[1]]
ord <- order(c1_markers$mean.AUC,
decreasing = TRUE)
top.markers <- head(rownames(c1_markers[ord,]))
plotExpression(sce,
features = top.markers,
x = "label",
color_by = "label")
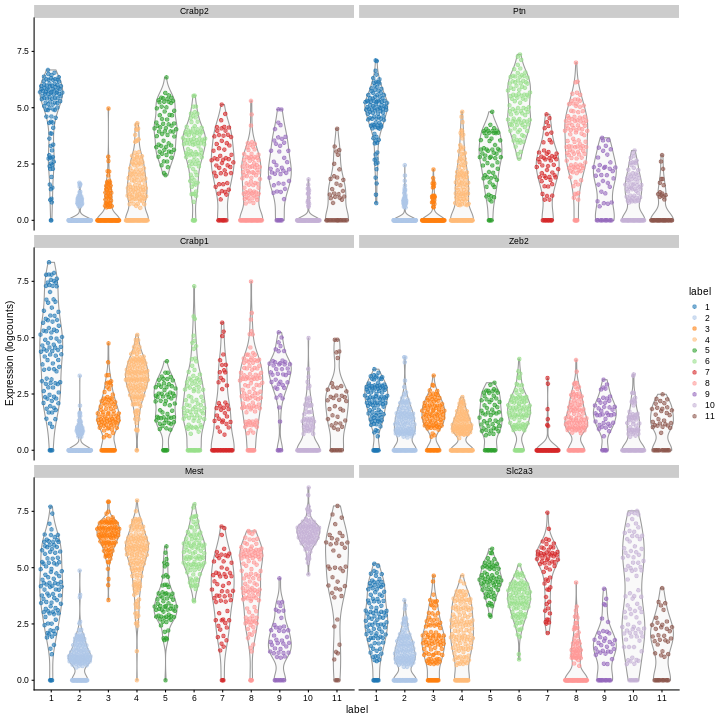
Clearly, not every marker gene distinguishes cluster 1 from every other cluster. However, with a combination of multiple marker genes it’s possible to clearly identify gene patterns that are unique to cluster 1. It’s sort of like the 20 questions game - with answers to the right questions about a cell (e.g. “Do you highly express Ptn?”), you can clearly identify what cluster it falls in.
Challenge
Looking at the last plot, what clusters are most difficult to distinguish from cluster 1? Now re-run the UMAP plot from the previous section. Do the difficult-to-distinguish clusters make sense?
You can see that at least among the top markers, cluster 6 (pale green) tends to have the least separation from cluster 1.
R
plotReducedDim(sce, "UMAP", color_by = "label")
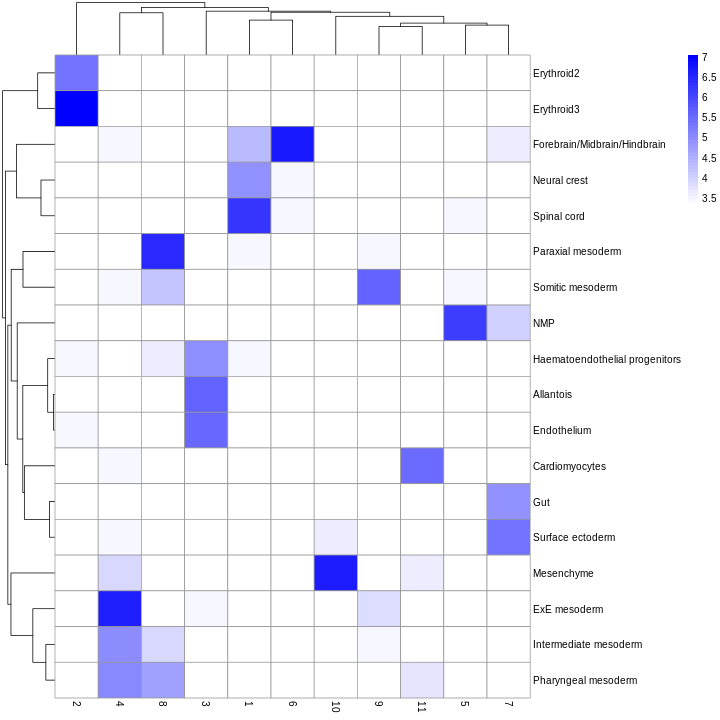
Looking at the UMAP again, we can see that the marker gene overlap of clusters 1 and 6 makes sense. They’re right next to each other on the UMAP. They’re probably closely related cell types, and a less granular clustering would probably lump them together.
Cell type annotation
The most challenging task in scRNA-seq data analysis is arguably the interpretation of the results. Obtaining clusters of cells is fairly straightforward, but it is more difficult to determine what biological state is represented by each of those clusters. Doing so requires us to bridge the gap between the current dataset and prior biological knowledge, and the latter is not always available in a consistent and quantitative manner. Indeed, even the concept of a “cell type” is not clearly defined, with most practitioners possessing a “I’ll know it when I see it” intuition that is not amenable to computational analysis. As such, interpretation of scRNA-seq data is often manual and a common bottleneck in the analysis workflow.
To expedite this step, we can use various computational approaches that exploit prior information to assign meaning to an uncharacterized scRNA-seq dataset. The most obvious sources of prior information are the curated gene sets associated with particular biological processes, e.g., from the Gene Ontology (GO) or the Kyoto Encyclopedia of Genes and Genomes (KEGG) collections. Alternatively, we can directly compare our expression profiles to published reference datasets where each sample or cell has already been annotated with its putative biological state by domain experts. Here, we will demonstrate both approaches on the wild-type chimera dataset.
Assigning cell labels from reference data
A conceptually straightforward annotation approach is to compare the single-cell expression profiles with previously annotated reference datasets. Labels can then be assigned to each cell in our uncharacterized test dataset based on the most similar reference sample(s), for some definition of “similar”. This is a standard classification challenge that can be tackled by standard machine learning techniques such as random forests and support vector machines. Any published and labelled RNA-seq dataset (bulk or single-cell) can be used as a reference, though its reliability depends greatly on the expertise of the original authors who assigned the labels in the first place.
In this section, we will demonstrate the use of the SingleR method for cell type annotation Aran et al., 2019. This method assigns labels to cells based on the reference samples with the highest Spearman rank correlations, using only the marker genes between pairs of labels to focus on the relevant differences between cell types. It also performs a fine-tuning step for each cell where the correlations are recomputed with just the marker genes for the top-scoring labels. This aims to resolve any ambiguity between those labels by removing noise from irrelevant markers for other labels. Further details can be found in the SingleR book from which most of the examples here are derived.
Callout
Remember, the quality of reference-based cell type annotation can only be as good as the cell type assignments in the reference. Garbage in, garbage out. In practice, it’s worthwhile to spend time carefully assessing your to make sure the original assignments make sense and that it’s compatible with the query dataset you’re trying to annotate.
Here we take a single sample from EmbryoAtlasData as our
reference dataset. In practice you would want to take more/all samples,
possibly with batch-effect correction (see the next episode).
R
ref <- EmbryoAtlasData(samples = 29)
ref
OUTPUT
class: SingleCellExperiment
dim: 29452 7569
metadata(0):
assays(1): counts
rownames(29452): ENSMUSG00000051951 ENSMUSG00000089699 ...
ENSMUSG00000096730 ENSMUSG00000095742
rowData names(2): ENSEMBL SYMBOL
colnames(7569): cell_95727 cell_95728 ... cell_103294 cell_103295
colData names(17): cell barcode ... colour sizeFactor
reducedDimNames(2): pca.corrected umap
mainExpName: NULL
altExpNames(0):In order to reduce the computational load, we subsample the dataset to 1,000 cells.
R
set.seed(123)
ind <- sample(ncol(ref), 1000)
ref <- ref[,ind]
You can see we have an assortment of different cell types in the reference (with varying frequency):
R
tab <- sort(table(ref$celltype), decreasing = TRUE)
tab
OUTPUT
Forebrain/Midbrain/Hindbrain Erythroid3
131 75
Paraxial mesoderm NMP
69 51
ExE mesoderm Surface ectoderm
49 47
Allantois Mesenchyme
46 45
Spinal cord Pharyngeal mesoderm
45 41
ExE endoderm Neural crest
38 35
Gut Haematoendothelial progenitors
30 27
Intermediate mesoderm Cardiomyocytes
27 26
Somitic mesoderm Endothelium
25 23
Erythroid2 Def. endoderm
11 3
Erythroid1 Blood progenitors 1
2 1
Blood progenitors 2 Caudal Mesoderm
1 1
PGC
1 We need the normalized log counts, so we add those on:
R
ref <- logNormCounts(ref)
Some cleaning - remove cells of the reference dataset for which the cell type annotation is missing:
R
nna <- !is.na(ref$celltype)
ref <- ref[,nna]
Also remove cell types of very low abundance (here less than 10 cells) to remove noise prior to subsequent annotation tasks.
R
abu.ct <- names(tab)[tab >= 10]
ind <- ref$celltype %in% abu.ct
ref <- ref[,ind]
Restrict to genes shared between query and reference dataset.
R
rownames(ref) <- rowData(ref)$SYMBOL
shared_genes <- intersect(rownames(sce), rownames(ref))
sce <- sce[shared_genes,]
ref <- ref[shared_genes,]
Convert sparse assay matrices to regular dense matrices for input to SingleR:
R
sce.mat <- as.matrix(assay(sce, "logcounts"))
ref.mat <- as.matrix(assay(ref, "logcounts"))
Finally, run SingleR with the query and reference datasets:
R
res <- SingleR(test = sce.mat,
ref = ref.mat,
labels = ref$celltype)
res
OUTPUT
DataFrame with 1000 rows and 4 columns
scores labels delta.next
<matrix> <character> <numeric>
cell_11995 0.348586:0.335451:0.314515:... Forebrain/Midbrain/H.. 0.1285110
cell_10294 0.273570:0.260013:0.298932:... Erythroid3 0.1381951
cell_9963 0.328538:0.291288:0.475611:... Endothelium 0.2193295
cell_11610 0.281161:0.269245:0.299961:... Erythroid3 0.0359215
cell_10910 0.422454:0.346897:0.355947:... ExE mesoderm 0.0984285
... ... ... ...
cell_11597 0.323805:0.292967:0.300485:... NMP 0.1663369
cell_9807 0.464466:0.374189:0.381698:... Mesenchyme 0.0833019
cell_10095 0.341721:0.288215:0.485324:... Endothelium 0.0889931
cell_11706 0.267487:0.240215:0.286012:... Erythroid2 0.0350557
cell_11860 0.345786:0.343437:0.313994:... Forebrain/Midbrain/H.. 0.0117001
pruned.labels
<character>
cell_11995 Forebrain/Midbrain/H..
cell_10294 Erythroid3
cell_9963 Endothelium
cell_11610 Erythroid3
cell_10910 ExE mesoderm
... ...
cell_11597 NMP
cell_9807 Mesenchyme
cell_10095 Endothelium
cell_11706 Erythroid2
cell_11860 Forebrain/Midbrain/H..We inspect the results using a heatmap of the per-cell and label scores. Ideally, each cell should exhibit a high score in one label relative to all of the others, indicating that the assignment to that label was unambiguous.
R
plotScoreHeatmap(res)
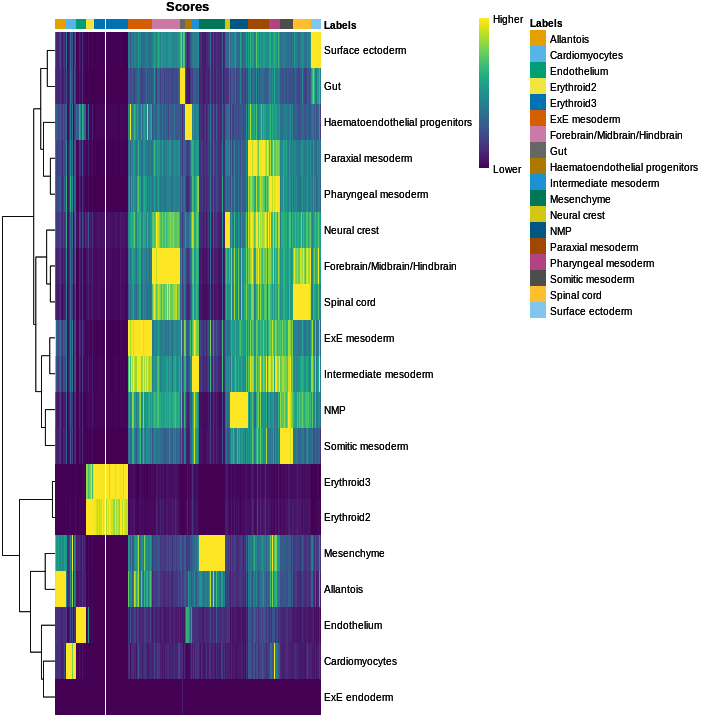
We obtained fairly unambiguous predictions for mesenchyme and endothelial cells, whereas we see expectedly more ambiguity between the two erythroid cell populations.
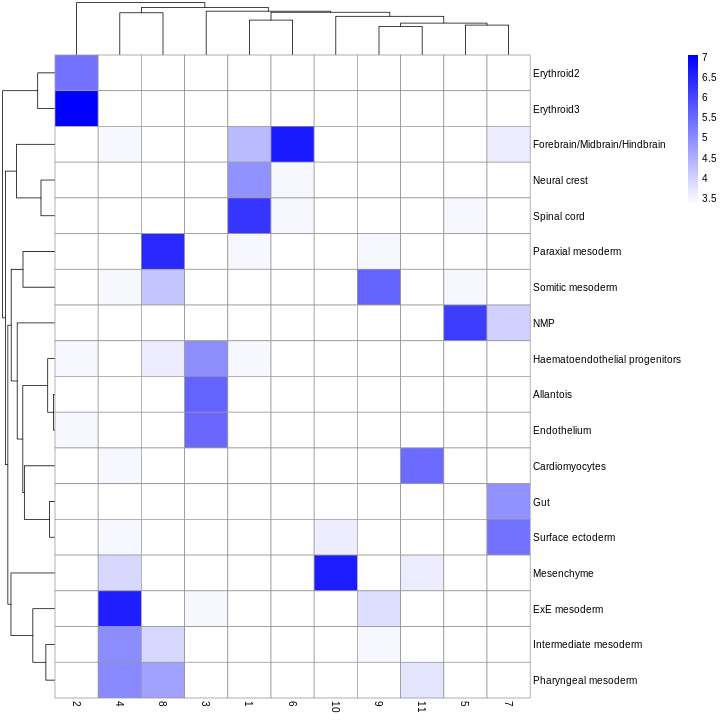
We can also compare the cell type assignments with the unsupervised clustering results to determine the identity of each cluster. Here, several cell type classes are nested within the same cluster, indicating that these clusters are composed of several transcriptomically similar cell populations. On the other hand, there are also instances where we have several clusters for the same cell type, indicating that the clustering represents finer subdivisions within these cell types.
R
tab <- table(anno = res$pruned.labels, cluster = colLabels(sce))
pheatmap(log2(tab + 10), color = colorRampPalette(c("white", "blue"))(101))
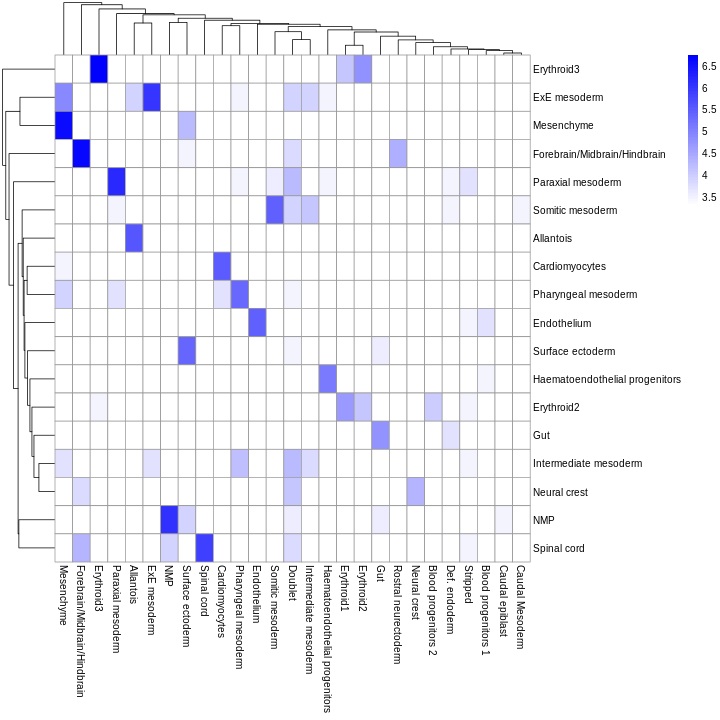
As it so happens, we are in the fortunate position where our test dataset also contains independently defined labels. We see strong consistency between the two sets of labels, indicating that our automatic annotation is comparable to that generated manually by domain experts.
R
tab <- table(res$pruned.labels, sce$celltype.mapped)
pheatmap(log2(tab + 10), color = colorRampPalette(c("white", "blue"))(101))
Challenge
Assign the SingleR annotations as a column in the colData for the
query object sce.
R
sce$SingleR_label = res$pruned.labels
Assigning cell labels from gene sets
A related strategy is to explicitly identify sets of marker genes that are highly expressed in each individual cell. This does not require matching of individual cells to the expression values of the reference dataset, which is faster and more convenient when only the identities of the markers are available. We demonstrate this approach using cell type markers derived from the mouse embryo atlas dataset.
R
wilcox.z <- pairwiseWilcox(ref, ref$celltype, lfc = 1, direction = "up")
markers.z <- getTopMarkers(wilcox.z$statistics, wilcox.z$pairs,
pairwise = FALSE, n = 50)
lengths(markers.z)
OUTPUT
Allantois Cardiomyocytes
106 106
Endothelium Erythroid2
103 54
Erythroid3 ExE endoderm
84 102
ExE mesoderm Forebrain/Midbrain/Hindbrain
97 97
Gut Haematoendothelial progenitors
90 71
Intermediate mesoderm Mesenchyme
70 118
Neural crest NMP
66 91
Paraxial mesoderm Pharyngeal mesoderm
88 85
Somitic mesoderm Spinal cord
86 91
Surface ectoderm
92 Our test dataset will be as before the wild-type chimera dataset.
R
sce
OUTPUT
class: SingleCellExperiment
dim: 29411 1000
metadata(0):
assays(2): counts logcounts
rownames(29411): Xkr4 Gm1992 ... Vmn2r122 CAAA01147332.1
rowData names(2): ENSEMBL SYMBOL
colnames(1000): cell_11995 cell_10294 ... cell_11706 cell_11860
colData names(14): cell barcode ... clust2 SingleR_label
reducedDimNames(4): pca.corrected.E7.5 pca.corrected.E8.5 PCA UMAP
mainExpName: NULL
altExpNames(0):We use the AUCell package to identify marker sets that are highly expressed in each cell. This method ranks genes by their expression values within each cell and constructs a response curve of the number of genes from each marker set that are present with increasing rank. It then computes the area under the curve (AUC) for each marker set, quantifying the enrichment of those markers among the most highly expressed genes in that cell. This is roughly similar to performing a Wilcoxon rank sum test between genes in and outside of the set, but involving only the top ranking genes by expression in each cell.
R
all.sets <- lapply(names(markers.z),
function(x) GeneSet(markers.z[[x]], setName = x))
all.sets <- GeneSetCollection(all.sets)
all.sets
OUTPUT
GeneSetCollection
names: Allantois, Cardiomyocytes, ..., Surface ectoderm (19 total)
unique identifiers: Phlda2, Spin2c, ..., Akr7a5 (991 total)
types in collection:
geneIdType: NullIdentifier (1 total)
collectionType: NullCollection (1 total)R
rankings <- AUCell_buildRankings(as.matrix(counts(sce)),
plotStats = FALSE, verbose = FALSE)
cell.aucs <- AUCell_calcAUC(all.sets, rankings)
results <- t(assay(cell.aucs))
head(results)
OUTPUT
gene sets
cells Allantois Cardiomyocytes Endothelium Erythroid2 Erythroid3
cell_11995 0.0691 0.0536 0.0459 0.1056 0.0948
cell_10294 0.0384 0.0370 0.0451 0.4910 0.5153
cell_9963 0.2177 0.1011 0.4380 0.1070 0.1087
cell_11610 0.0108 0.0428 0.0347 0.4687 0.4555
cell_10910 0.1868 0.0766 0.0869 0.0766 0.0682
cell_11021 0.0695 0.0596 0.0465 0.0991 0.0993
gene sets
cells ExE endoderm ExE mesoderm Forebrain/Midbrain/Hindbrain Gut
cell_11995 0.0342 0.1324 0.3173 0.1011
cell_10294 0.0680 0.0172 0.0439 0.0458
cell_9963 0.0686 0.1147 0.1116 0.1237
cell_11610 0.0573 0.0202 0.0460 0.0268
cell_10910 0.0764 0.3255 0.1747 0.1816
cell_11021 0.0680 0.2029 0.2500 0.1277
gene sets
cells Haematoendothelial progenitors Intermediate mesoderm Mesenchyme
cell_11995 0.0396 0.1627 0.0869
cell_10294 0.0371 0.0387 0.0369
cell_9963 0.3906 0.1157 0.2338
cell_11610 0.0258 0.0444 0.0324
cell_10910 0.1477 0.2265 0.2042
cell_11021 0.0473 0.2016 0.0814
gene sets
cells Neural crest NMP Paraxial mesoderm Pharyngeal mesoderm
cell_11995 0.208 0.1805 0.1889 0.1844
cell_10294 0.109 0.0445 0.0226 0.0263
cell_9963 0.145 0.1045 0.1706 0.1561
cell_11610 0.107 0.0640 0.0195 0.0294
cell_10910 0.135 0.2025 0.1437 0.1686
cell_11021 0.168 0.3432 0.1255 0.1515
gene sets
cells Somitic mesoderm Spinal cord Surface ectoderm
cell_11995 0.1279 0.2592 0.1611
cell_10294 0.0203 0.0633 0.0468
cell_9963 0.1197 0.1014 0.0850
cell_11610 0.0424 0.0692 0.0332
cell_10910 0.1787 0.1521 0.1043
cell_11021 0.2259 0.1974 0.1509We assign cell type identity to each cell in the test dataset by taking the marker set with the top AUC as the label for that cell. Our new labels mostly agree with the original annotation (and, thus, also with the reference-based annotation). Instances where the original annotation is divided into several new label groups typically points to large overlaps in their marker sets. In the absence of prior annotation, a more general diagnostic check is to compare the assigned labels to cluster identities, under the expectation that most cells of a single cluster would have the same label (or, if multiple labels are present, they should at least represent closely related cell states). We only print out the top-left corner of the table here, but you should try looking at the whole thing:
R
new.labels <- colnames(results)[max.col(results)]
tab <- table(new.labels, sce$celltype.mapped)
tab[1:4,1:4]
OUTPUT
new.labels Allantois Blood progenitors 1 Blood progenitors 2
Allantois 44 0 0
Cardiomyocytes 0 0 0
Endothelium 0 3 0
Erythroid2 0 1 7
new.labels Cardiomyocytes
Allantois 0
Cardiomyocytes 32
Endothelium 0
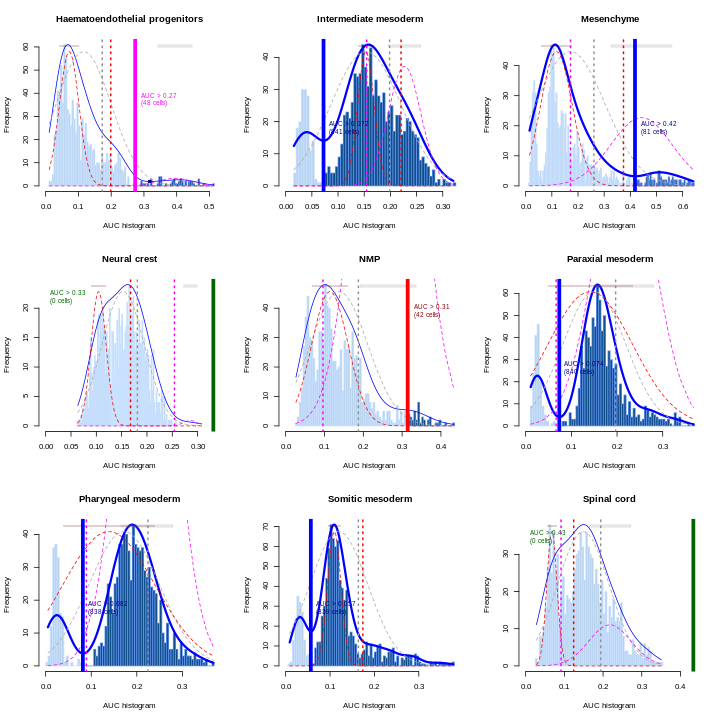
Erythroid2 0As a diagnostic measure, we examine the distribution of AUCs across cells for each label. In heterogeneous populations, the distribution for each label should be bimodal with one high-scoring peak containing cells of that cell type and a low-scoring peak containing cells of other types. The gap between these two peaks can be used to derive a threshold for whether a label is “active” for a particular cell. (In this case, we simply take the single highest-scoring label per cell as the labels should be mutually exclusive.) In populations where a particular cell type is expected, lack of clear bimodality for the corresponding label may indicate that its gene set is not sufficiently informative.
R
par(mfrow = c(3,3))
AUCell_exploreThresholds(cell.aucs[1:9], plotHist = TRUE, assign = TRUE)
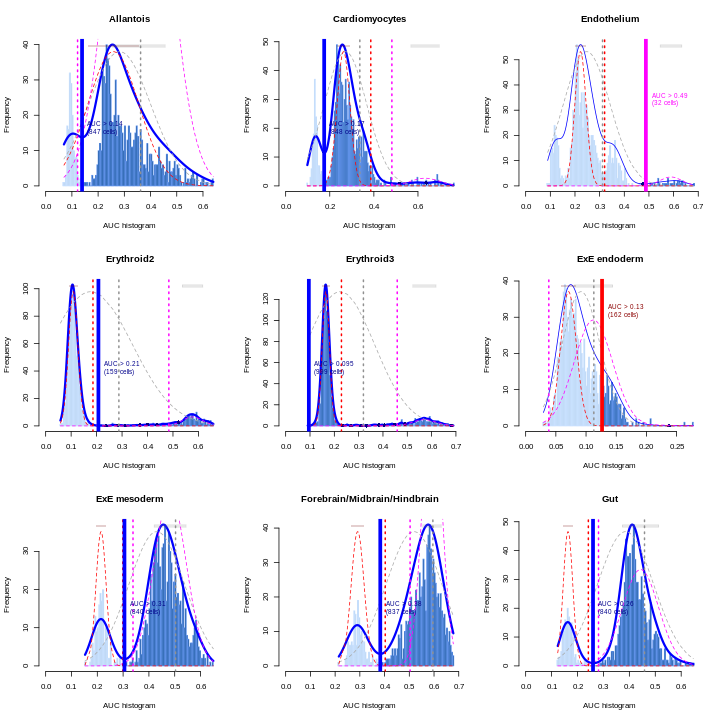
Shown is the distribution of AUCs in the wild-type chimera dataset for each label in the embryo atlas dataset. The blue curve represents the density estimate, the red curve represents a fitted two-component mixture of normals, the pink curve represents a fitted three-component mixture, and the grey curve represents a fitted normal distribution. Vertical lines represent threshold estimates corresponding to each estimate of the distribution.
Challenge
Inspect the diagnostics for the next nine cell types. Do they look okay?
R
par(mfrow = c(3,3))
AUCell_exploreThresholds(cell.aucs[10:18], plotHist = TRUE, assign = TRUE)
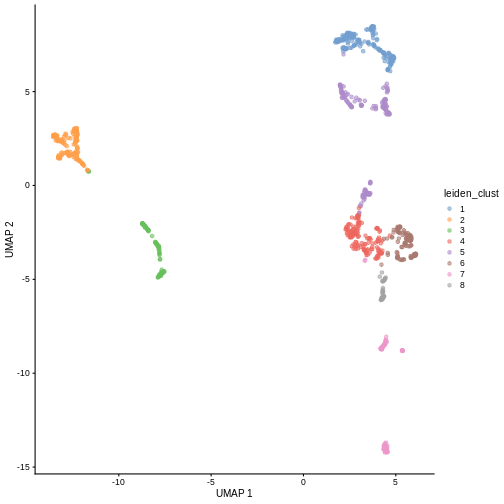
Exercises
Exercise 1: Clustering
The Leiden
algorithm is similar to the Louvain algorithm, but it is faster and
has been shown to result in better connected communities. Modify the
above call to clusterCells to carry out the community
detection with the Leiden algorithm instead. Visualize the results in a
UMAP plot.
The NNGraphParam constructor has an argument
cluster.args. This allows to specify arguments passed on to
the cluster_leiden function from the igraph
package. Use the cluster.args argument to parameterize the
clustering to use modularity as the objective function and a resolution
parameter of 0.5.
R
arg_list <- list(objective_function = "modularity",
resolution_parameter = .5)
sce$leiden_clust <- clusterCells(sce, use.dimred = "PCA",
BLUSPARAM = NNGraphParam(cluster.fun = "leiden",
cluster.args = arg_list))
plotReducedDim(sce, "UMAP", color_by = "leiden_clust")
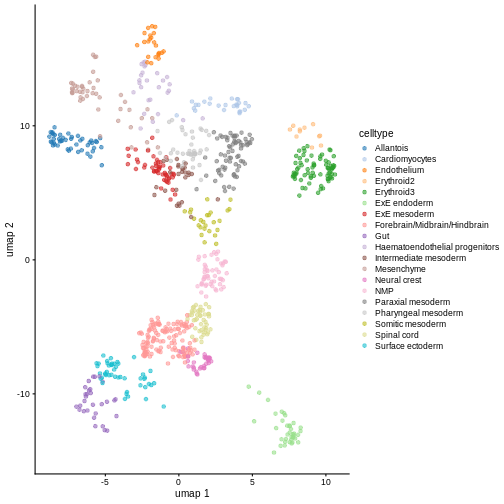
Exercise 2: Reference marker genes
Identify the marker genes in the reference single cell experiment,
using the celltype labels that come with the dataset as the
groups. Compare the top 100 marker genes of two cell types that are
close in UMAP space. Do they share similar marker sets?
R
markers <- scoreMarkers(ref, groups = ref$celltype)
markers
OUTPUT
List of length 19
names(19): Allantois Cardiomyocytes ... Spinal cord Surface ectodermR
# It comes with UMAP precomputed too
plotReducedDim(ref, dimred = "umap", color_by = "celltype")
R
# Repetitive work -> write a function
order_marker_df <- function(m_df, n = 100) {
ord <- order(m_df$mean.AUC, decreasing = TRUE)
rownames(m_df[ord,][1:n,])
}
x <- order_marker_df(markers[["Erythroid2"]])
y <- order_marker_df(markers[["Erythroid3"]])
length(intersect(x,y)) / 100
OUTPUT
[1] 0.66Turns out there’s pretty substantial overlap between
Erythroid2 and Erythroid3. It would also be
interesting to plot the expression of the set difference to confirm that
the remainder are the the genes used to distinguish these two types from
each other.
Extension Challenge 1: Group pair comparisons
Why do you think marker genes are found by aggregating pairwise comparisons rather than iteratively comparing each cluster to all other clusters?
One important reason why is because averages over all other clusters can be sensitive to the cell type composition. If a rare cell type shows up in one sample, the most discriminative marker genes found in this way could be very different from those found in another sample where the rare cell type is absent.
Generally, it’s good to keep in mind that the concept of “everything else” is not a stable basis for comparison. Read that sentence again, because its a subtle but broadly applicable point. Think about it and you can probably identify analogous issues in fields outside of single-cell analysis. It frequently comes up when comparisons between multiple categories are involved.
Extension Challenge 2: Parallelizing SingleR
SingleR can be computationally expensive. How do you set it to run in parallel?
Use BiocParallel and the BPPARAM argument!
This example will set it to use four cores on your laptop, but you can
also configure BiocParallel to use cluster jobs.
R
library(BiocParallel)
my_bpparam <- MulticoreParam(workers = 4)
res2 <- SingleR(test = sce.mat,
ref = ref.mat,
labels = ref$celltype,
BPPARAM = my_bpparam)
BiocParallel is the most common way to enable parallel
computation in Bioconductor packages, so you can expect to see it
elsewhere outside of SingleR.
Extension Challenge 3: Critical inspection of diagnostics
The first set of AUCell diagnostics don’t look so good for some of the examples here. Which ones? Why?
The example that jumps out most strongly to the eye is ExE endoderm, which doesn’t show clear separate modes. Simultaneously, Endothelium seems to have three or four modes.
Remember, this is an exploratory diagnostic, not the final word! At this point it’d be good to engage in some critical inspection of the results. Maybe we don’t have enough / the best marker genes. In this particular case, the fact that we subsetted the reference set to 1000 cells probably didn’t help.
Further Reading
- OSCA book, Chapters 5-7
- Assigning cell types with SingleR (the book).
- The AUCell package vignette.
Key Points
- The two main approaches for cell type annotation are 1) manual annotation of clusters based on marker gene expression, and 2) computational annotation based on annotation transfer from reference datasets or marker gene set enrichment testing.
- For manual annotation, cells are first clustered with unsupervised methods such as graph-based clustering followed by community detection algorithms such as Louvain or Leiden.
- The
clusterCellsfunction from the scran package provides different algorithms that are commonly used for the clustering of scRNA-seq data. - Once clusters have been obtained, cell type labels are then manually assigned to cell clusters by matching cluster-specific upregulated marker genes with prior knowledge of cell-type markers.
- The
scoreMarkersfunction from the scran package package can be used to find candidate marker genes for clusters of cells by ranking differential expression between pairs of clusters. - Computational annotation using published reference datasets or curated gene sets provides a fast, automated, and reproducible alternative to the manual annotation of cell clusters based on marker gene expression.
- The SingleR package is a popular choice for reference-based annotation and assigns labels to cells based on the reference samples with the highest Spearman rank correlations.
- The AUCell package provides an enrichment test to identify curated marker sets that are highly expressed in each cell.
Session Info
R
sessionInfo()
OUTPUT
R version 4.4.1 (2024-06-14)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 22.04.5 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.10.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.10.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
time zone: UTC
tzcode source: system (glibc)
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] GSEABase_1.66.0 graph_1.82.0
[3] annotate_1.82.0 XML_3.99-0.16.1
[5] AnnotationDbi_1.66.0 pheatmap_1.0.12
[7] scran_1.32.0 scater_1.32.0
[9] ggplot2_3.5.1 scuttle_1.14.0
[11] bluster_1.14.0 SingleR_2.6.0
[13] MouseGastrulationData_1.18.0 SpatialExperiment_1.14.0
[15] SingleCellExperiment_1.26.0 SummarizedExperiment_1.34.0
[17] Biobase_2.64.0 GenomicRanges_1.56.0
[19] GenomeInfoDb_1.40.1 IRanges_2.38.0
[21] S4Vectors_0.42.0 BiocGenerics_0.50.0
[23] MatrixGenerics_1.16.0 matrixStats_1.3.0
[25] AUCell_1.26.0 BiocStyle_2.32.0
loaded via a namespace (and not attached):
[1] RColorBrewer_1.1-3 jsonlite_1.8.8
[3] magrittr_2.0.3 ggbeeswarm_0.7.2
[5] magick_2.8.3 farver_2.1.2
[7] rmarkdown_2.27 zlibbioc_1.50.0
[9] vctrs_0.6.5 memoise_2.0.1
[11] DelayedMatrixStats_1.26.0 htmltools_0.5.8.1
[13] S4Arrays_1.4.1 AnnotationHub_3.12.0
[15] curl_5.2.1 BiocNeighbors_1.22.0
[17] SparseArray_1.4.8 htmlwidgets_1.6.4
[19] plotly_4.10.4 cachem_1.1.0
[21] igraph_2.0.3 mime_0.12
[23] lifecycle_1.0.4 pkgconfig_2.0.3
[25] rsvd_1.0.5 Matrix_1.7-0
[27] R6_2.5.1 fastmap_1.2.0
[29] GenomeInfoDbData_1.2.12 digest_0.6.35
[31] colorspace_2.1-0 dqrng_0.4.1
[33] irlba_2.3.5.1 ExperimentHub_2.12.0
[35] RSQLite_2.3.7 beachmat_2.20.0
[37] labeling_0.4.3 filelock_1.0.3
[39] fansi_1.0.6 httr_1.4.7
[41] abind_1.4-5 compiler_4.4.1
[43] bit64_4.0.5 withr_3.0.0
[45] BiocParallel_1.38.0 viridis_0.6.5
[47] DBI_1.2.3 highr_0.11
[49] R.utils_2.12.3 MASS_7.3-60.2
[51] rappdirs_0.3.3 DelayedArray_0.30.1
[53] rjson_0.2.21 tools_4.4.1
[55] vipor_0.4.7 beeswarm_0.4.0
[57] R.oo_1.26.0 glue_1.7.0
[59] nlme_3.1-164 grid_4.4.1
[61] cluster_2.1.6 generics_0.1.3
[63] gtable_0.3.5 R.methodsS3_1.8.2
[65] tidyr_1.3.1 data.table_1.15.4
[67] BiocSingular_1.20.0 ScaledMatrix_1.12.0
[69] metapod_1.12.0 utf8_1.2.4
[71] XVector_0.44.0 ggrepel_0.9.5
[73] BiocVersion_3.19.1 pillar_1.9.0
[75] limma_3.60.2 BumpyMatrix_1.12.0
[77] splines_4.4.1 dplyr_1.1.4
[79] BiocFileCache_2.12.0 lattice_0.22-6
[81] survival_3.6-4 FNN_1.1.4
[83] renv_1.0.11 bit_4.0.5
[85] tidyselect_1.2.1 locfit_1.5-9.9
[87] Biostrings_2.72.1 knitr_1.47
[89] gridExtra_2.3 edgeR_4.2.0
[91] xfun_0.44 mixtools_2.0.0
[93] statmod_1.5.0 UCSC.utils_1.0.0
[95] lazyeval_0.2.2 yaml_2.3.8
[97] evaluate_0.23 codetools_0.2-20
[99] kernlab_0.9-32 tibble_3.2.1
[101] BiocManager_1.30.23 cli_3.6.2
[103] uwot_0.2.2 xtable_1.8-4
[105] segmented_2.1-0 munsell_0.5.1
[107] Rcpp_1.0.12 dbplyr_2.5.0
[109] png_0.1-8 parallel_4.4.1
[111] blob_1.2.4 sparseMatrixStats_1.16.0
[113] viridisLite_0.4.2 scales_1.3.0
[115] purrr_1.0.2 crayon_1.5.2
[117] rlang_1.1.3 formatR_1.14
[119] cowplot_1.1.3 KEGGREST_1.44.0