Content from Introduction to Bioconductor and the SingleCellExperiment class
Last updated on 2024-11-11 | Edit this page
Overview
Questions
- What is Bioconductor?
- How is single-cell data stored in the Bioconductor ecosystem?
- What is a
SingleCellExperimentobject?
Objectives
- Install and update Bioconductor packages.
- Load data generated with common single-cell technologies as
SingleCellExperimentobjects. - Inspect and manipulate
SingleCellExperimentobjects.
Bioconductor
Overview
Within the R ecosystem, the Bioconductor project provides tools for the analysis and comprehension of high-throughput genomics data. The scope of the project covers microarray data, various forms of sequencing (RNA-seq, ChIP-seq, bisulfite, genotyping, etc.), proteomics, flow cytometry and more. One of Bioconductor’s main selling points is the use of common data structures to promote interoperability between packages, allowing code written by different people (from different organizations, in different countries) to work together seamlessly in complex analyses.
Installing Bioconductor Packages
The default repository for R packages is the Comprehensive R Archive Network (CRAN), which is home to over 13,000 different R packages. We can easily install packages from CRAN - say, the popular ggplot2 package for data visualization - by opening up R and typing in:
R
install.packages("ggplot2")
In our case, however, we want to install Bioconductor packages. These packages are located in a separate repository hosted by Bioconductor, so we first install the BiocManager package to easily connect to the Bioconductor servers.
R
install.packages("BiocManager")
After that, we can use BiocManager’s
install() function to install any package from
Bioconductor. For example, the code chunk below uses this approach to
install the SingleCellExperiment
package.
R
BiocManager::install("SingleCellExperiment")
Should we forget, the same instructions are present on the landing
page of any Bioconductor package. For example, looking at the scater
package page on Bioconductor, we can see the following copy-pasteable
instructions:
R
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("scater")
Packages only need to be installed once, and then they are available for all subsequent uses of a particular R installation. There is no need to repeat the installation every time we start R.
Finding relevant packages
To find relevant Bioconductor packages, one useful resource is the BiocViews page. This provides a hierarchically organized view of annotations associated with each Bioconductor package. For example, under the “Software” label, we might be interested in a particular “Technology” such as… say, “SingleCell”. This gives us a listing of all Bioconductor packages that might be useful for our single-cell data analyses. CRAN uses the similar concept of “Task views”, though this is understandably more general than genomics. For example, the Cluster task view page lists an assortment of packages that are relevant to cluster analyses.
Staying up to date
Updating all R/Bioconductor packages is as simple as running
BiocManager::install() without any arguments. This will
check for more recent versions of each package (within a Bioconductor
release) and prompt the user to update if any are available.
R
BiocManager::install()
This might take some time if many packages need to be updated, but is typically recommended to avoid issues resulting from outdated package versions.
The SingleCellExperiment class
Setup
We start by loading some libraries we’ll be using:
R
library(SingleCellExperiment)
library(MouseGastrulationData)
It is normal to see lot of startup messages when loading these packages.
Motivation and overview
One of the main strengths of the Bioconductor project lies in the use of a common data infrastructure that powers interoperability across packages.
Users should be able to analyze their data using functions from
different Bioconductor packages without the need to convert between
formats. To this end, the SingleCellExperiment class (from
the SingleCellExperiment package) serves as the common currency
for data exchange across 70+ single-cell-related Bioconductor
packages.
This class implements a data structure that stores all aspects of our single-cell data - gene-by-cell expression data, cell-wise metadata, and gene-wise annotation - and lets us manipulate them in an organized manner.
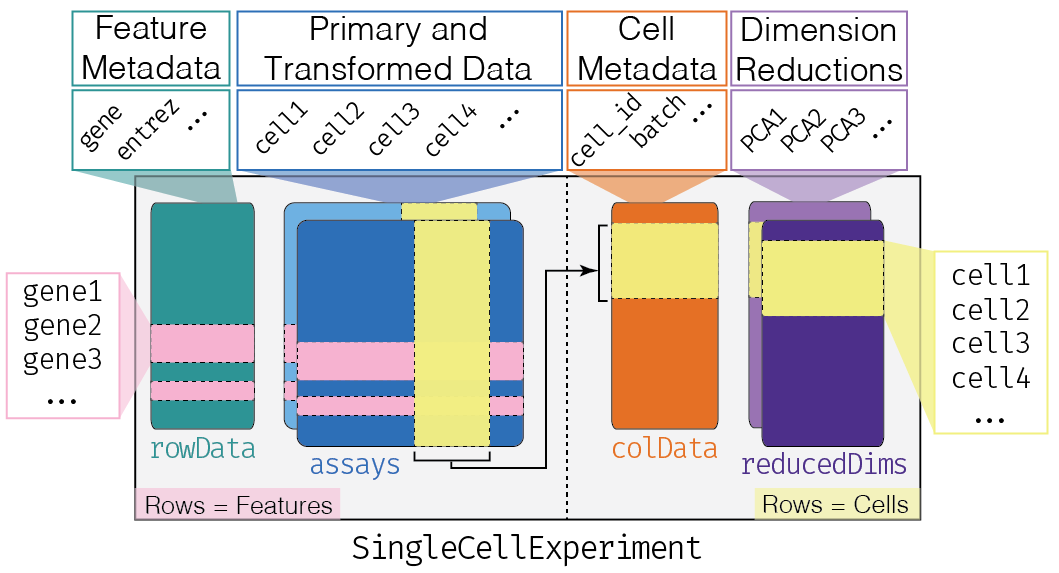
The complexity of the SingleCellExperiment container
might be a little bit intimidating in the beginning. One might be
tempted to use a simpler approach by just keeping all of these
components in separate objects, e.g. a matrix of counts, a
data.frame of sample metadata, a data.frame of
gene annotations, and so on.
There are two main disadvantages to this “from-scratch” approach:
- It requires a substantial amount of manual bookkeeping to keep the different data components in sync. If you performed a QC step that removed dead cells from the count matrix, you also had to remember to remove that same set of cells from the cell-wise metadata. Did you filtered out genes that did not display sufficient expression levels to be retained for further analysis? Then you would need to make sure to not forget to filter the gene metadata table too.
- All the downstream steps had to be “from scratch” as well. All the data munging, analysis, and visualization code had to be customized to the idiosyncrasies of a given input set.
Let’s look at an example dataset. WTChimeraData comes
from a study on mouse development Pijuan-Sala et
al.. The study profiles the effect of a transcription factor TAL1
and its influence on mouse development. Because mutations in this gene
can cause severe developmental issues, Tal1-/- cells (positive for
tdTomato, a fluorescent protein) were injected into wild-type
blastocysts (tdTomato-), forming chimeric embryos.
We can assign one sample to a SingleCellExperiment
object named sce like so:
R
sce <- WTChimeraData(samples = 5)
sce
OUTPUT
class: SingleCellExperiment
dim: 29453 2411
metadata(0):
assays(1): counts
rownames(29453): ENSMUSG00000051951 ENSMUSG00000089699 ...
ENSMUSG00000095742 tomato-td
rowData names(2): ENSEMBL SYMBOL
colnames(2411): cell_9769 cell_9770 ... cell_12178 cell_12179
colData names(11): cell barcode ... doub.density sizeFactor
reducedDimNames(2): pca.corrected.E7.5 pca.corrected.E8.5
mainExpName: NULL
altExpNames(0):We can think of this (and other) class as a container, that contains several different pieces of data in so-called slots. SingleCellExperiment objects come with dedicated methods for getting and setting the data in their slots.
Depending on the object, slots can contain different types of data (e.g., numeric matrices, lists, etc.). Here we’ll review the main slots of the SingleCellExperiment class as well as their getter/setter methods.
Challenge
Get the data for a different sample from WTChimeraData
(other than the fifth one).
Here we obtain the sixth sample and assign it to
sce6:
R
sce6 <- WTChimeraData(samples = 6)
sce6
assays
This is arguably the most fundamental part of the object that
contains the count matrix, and potentially other matrices with
transformed data. We can access the list of matrices with the
assays function and individual matrices with the
assay function. If one of these matrices is called
“counts”, we can use the special counts getter (likewise
for logcounts).
R
names(assays(sce))
OUTPUT
[1] "counts"R
counts(sce)[1:3, 1:3]
OUTPUT
3 x 3 sparse Matrix of class "dgCMatrix"
cell_9769 cell_9770 cell_9771
ENSMUSG00000051951 . . .
ENSMUSG00000089699 . . .
ENSMUSG00000102343 . . .You will notice that in this case we have a sparse matrix of class
dgTMatrix inside the object. More generally, any
“matrix-like” object can be used, e.g., dense matrices or HDF5-backed
matrices (as we will explore later in the Working
with large data episode).
colData and rowData
Conceptually, these are two data frames that annotate the columns and the rows of your assay, respectively.
One can interact with them as usual, e.g., by extracting columns or adding additional variables as columns.
R
colData(sce)[1:3, 1:4]
OUTPUT
DataFrame with 3 rows and 4 columns
cell barcode sample stage
<character> <character> <integer> <character>
cell_9769 cell_9769 AAACCTGAGACTGTAA 5 E8.5
cell_9770 cell_9770 AAACCTGAGATGCCTT 5 E8.5
cell_9771 cell_9771 AAACCTGAGCAGCCTC 5 E8.5R
rowData(sce)[1:3, 1:2]
OUTPUT
DataFrame with 3 rows and 2 columns
ENSEMBL SYMBOL
<character> <character>
ENSMUSG00000051951 ENSMUSG00000051951 Xkr4
ENSMUSG00000089699 ENSMUSG00000089699 Gm1992
ENSMUSG00000102343 ENSMUSG00000102343 Gm37381You can access columns of the colData with the $
accessor to quickly add cell-wise metadata to the
colData.
R
sce$my_sum <- colSums(counts(sce))
colData(sce)[1:3,]
OUTPUT
DataFrame with 3 rows and 12 columns
cell barcode sample stage tomato
<character> <character> <integer> <character> <logical>
cell_9769 cell_9769 AAACCTGAGACTGTAA 5 E8.5 TRUE
cell_9770 cell_9770 AAACCTGAGATGCCTT 5 E8.5 TRUE
cell_9771 cell_9771 AAACCTGAGCAGCCTC 5 E8.5 TRUE
pool stage.mapped celltype.mapped closest.cell doub.density
<integer> <character> <character> <character> <numeric>
cell_9769 3 E8.25 Mesenchyme cell_24159 0.02985045
cell_9770 3 E8.5 Endothelium cell_96660 0.00172753
cell_9771 3 E8.5 Allantois cell_134982 0.01338013
sizeFactor my_sum
<numeric> <numeric>
cell_9769 1.41243 27577
cell_9770 1.22757 29309
cell_9771 1.15439 28795Challenge
Add a column of gene-wise metadata to the rowData.
Here, we add a column named conservation that could
represent an evolutionary conservation score.
R
rowData(sce)$conservation <- rnorm(nrow(sce))
This is just an example for demonstration purposes, but in practice
it is convenient and simplifies data management to store any sort of
gene-wise information in the columns of the rowData.
The reducedDims
Everything that we have described so far (except for the
counts getter) is part of the
SummarizedExperiment class that
SingleCellExperiment extends. You can find a complete
lesson on the SummarizedExperiment class in Introduction
to data analysis with R and Bioconductor course.
One peculiarity of SingleCellExperiment is its ability
to store reduced dimension matrices within the object. These may include
PCA, t-SNE, UMAP, etc.
R
reducedDims(sce)
OUTPUT
List of length 2
names(2): pca.corrected.E7.5 pca.corrected.E8.5As for the other slots, we have the usual setter/getter, but it is somewhat rare to interact directly with these functions.
It is more common for other functions to store this
information in the object, e.g., the runPCA function from
the scater package.
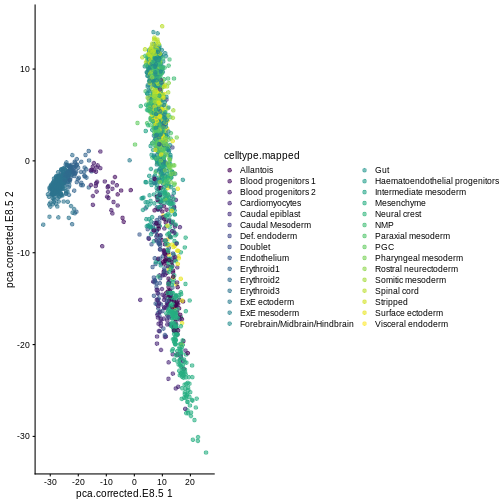
Here, we use scater’s plotReducedDim
function as an example of how to extract this information
indirectly from the objects. Note that one could obtain the
same results (somewhat less efficiently) by extracting the corresponding
reducedDim matrix and ggplot.
R
library(scater)
plotReducedDim(sce, "pca.corrected.E8.5", colour_by = "celltype.mapped")
Exercise 1
Create a SingleCellExperiment object “from scratch”.
That means: start from a matrix (either randomly generated
or with some fake data in it) and add one or more columns as
colData.
The SingleCellExperiment constructor function can be
used to create a new SingleCellExperiment object.
R
mat <- matrix(runif(30), ncol = 5)
my_sce <- SingleCellExperiment(assays = list(logcounts = mat))
my_sce$my_col_info = runif(5)
my_sce
OUTPUT
class: SingleCellExperiment
dim: 6 5
metadata(0):
assays(1): logcounts
rownames: NULL
rowData names(0):
colnames: NULL
colData names(1): my_col_info
reducedDimNames(0):
mainExpName: NULL
altExpNames(0):Exercise 2
Combine two SingleCellExperiment objects. The
MouseGastrulationData package contains several datasets.
Download sample 6 of the chimera experiment. Use the cbind
function to combine the new data with the sce object
created before.
R
sce <- WTChimeraData(samples = 5)
sce6 <- WTChimeraData(samples = 6)
combined_sce <- cbind(sce, sce6)
combined_sce
OUTPUT
class: SingleCellExperiment
dim: 29453 3458
metadata(0):
assays(1): counts
rownames(29453): ENSMUSG00000051951 ENSMUSG00000089699 ...
ENSMUSG00000095742 tomato-td
rowData names(2): ENSEMBL SYMBOL
colnames(3458): cell_9769 cell_9770 ... cell_13225 cell_13226
colData names(11): cell barcode ... doub.density sizeFactor
reducedDimNames(2): pca.corrected.E7.5 pca.corrected.E8.5
mainExpName: NULL
altExpNames(0):Further Reading
- OSCA book, Introduction
Key Points
- The Bioconductor project provides open-source software packages for the comprehension of high-throughput biological data.
- A
SingleCellExperimentobject is an extension of theSummarizedExperimentobject. -
SingleCellExperimentobjects contain specialized data fields for storing data unique to single-cell analyses, such as thereducedDimsfield.
References
- Pijuan-Sala B, Griffiths JA, Guibentif C et al. (2019). A single-cell molecular map of mouse gastrulation and early organogenesis. Nature 566, 7745:490-495.
Session Info
R
sessionInfo()
OUTPUT
R version 4.4.1 (2024-06-14)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 22.04.5 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.10.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.10.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
time zone: UTC
tzcode source: system (glibc)
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] scater_1.32.0 ggplot2_3.5.1
[3] scuttle_1.14.0 MouseGastrulationData_1.18.0
[5] SpatialExperiment_1.14.0 SingleCellExperiment_1.26.0
[7] SummarizedExperiment_1.34.0 Biobase_2.64.0
[9] GenomicRanges_1.56.0 GenomeInfoDb_1.40.1
[11] IRanges_2.38.0 S4Vectors_0.42.0
[13] BiocGenerics_0.50.0 MatrixGenerics_1.16.0
[15] matrixStats_1.3.0 BiocStyle_2.32.0
loaded via a namespace (and not attached):
[1] DBI_1.2.3 formatR_1.14
[3] gridExtra_2.3 rlang_1.1.3
[5] magrittr_2.0.3 compiler_4.4.1
[7] RSQLite_2.3.7 DelayedMatrixStats_1.26.0
[9] png_0.1-8 vctrs_0.6.5
[11] pkgconfig_2.0.3 crayon_1.5.2
[13] fastmap_1.2.0 dbplyr_2.5.0
[15] magick_2.8.3 XVector_0.44.0
[17] labeling_0.4.3 utf8_1.2.4
[19] rmarkdown_2.27 UCSC.utils_1.0.0
[21] ggbeeswarm_0.7.2 purrr_1.0.2
[23] bit_4.0.5 xfun_0.44
[25] zlibbioc_1.50.0 cachem_1.1.0
[27] beachmat_2.20.0 jsonlite_1.8.8
[29] blob_1.2.4 highr_0.11
[31] DelayedArray_0.30.1 BiocParallel_1.38.0
[33] irlba_2.3.5.1 parallel_4.4.1
[35] R6_2.5.1 Rcpp_1.0.12
[37] knitr_1.47 Matrix_1.7-0
[39] tidyselect_1.2.1 viridis_0.6.5
[41] abind_1.4-5 yaml_2.3.8
[43] codetools_0.2-20 curl_5.2.1
[45] lattice_0.22-6 tibble_3.2.1
[47] withr_3.0.0 KEGGREST_1.44.0
[49] BumpyMatrix_1.12.0 evaluate_0.23
[51] BiocFileCache_2.12.0 ExperimentHub_2.12.0
[53] Biostrings_2.72.1 pillar_1.9.0
[55] BiocManager_1.30.23 filelock_1.0.3
[57] renv_1.0.11 generics_0.1.3
[59] BiocVersion_3.19.1 sparseMatrixStats_1.16.0
[61] munsell_0.5.1 scales_1.3.0
[63] glue_1.7.0 tools_4.4.1
[65] AnnotationHub_3.12.0 BiocNeighbors_1.22.0
[67] ScaledMatrix_1.12.0 cowplot_1.1.3
[69] grid_4.4.1 AnnotationDbi_1.66.0
[71] colorspace_2.1-0 GenomeInfoDbData_1.2.12
[73] beeswarm_0.4.0 BiocSingular_1.20.0
[75] vipor_0.4.7 cli_3.6.2
[77] rsvd_1.0.5 rappdirs_0.3.3
[79] fansi_1.0.6 viridisLite_0.4.2
[81] S4Arrays_1.4.1 dplyr_1.1.4
[83] gtable_0.3.5 digest_0.6.35
[85] ggrepel_0.9.5 SparseArray_1.4.8
[87] farver_2.1.2 rjson_0.2.21
[89] memoise_2.0.1 htmltools_0.5.8.1
[91] lifecycle_1.0.4 httr_1.4.7
[93] mime_0.12 bit64_4.0.5 Content from Exploratory data analysis and quality control
Last updated on 2024-11-11 | Edit this page
Overview
Questions
- How do I examine the quality of single-cell data?
- What data visualizations should I use during quality control in a single-cell analysis?
- How do I prepare single-cell data for analysis?
Objectives
- Determine and communicate the quality of single-cell data.
- Identify and filter empty droplets and doublets.
- Perform normalization, feature selection, and dimensionality reduction as parts of a typical single-cell analysis pipeline.
Setup and experimental design
As mentioned in the introduction, in this tutorial we will use the wild-type data from the Tal1 chimera experiment. These data are available through the MouseGastrulationData Bioconductor package, which contains several datasets.
In particular, the package contains the following samples that we will use for the tutorial:
- Sample 5: E8.5 injected cells (tomato positive), pool 3
- Sample 6: E8.5 host cells (tomato negative), pool 3
- Sample 7: E8.5 injected cells (tomato positive), pool 4
- Sample 8: E8.5 host cells (tomato negative), pool 4
- Sample 9: E8.5 injected cells (tomato positive), pool 5
- Sample 10: E8.5 host cells (tomato negative), pool 5
We start our analysis by selecting only sample 5, which contains the injected cells in one biological replicate. We download the “raw” data that contains all the droplets for which we have sequenced reads.
R
library(MouseGastrulationData)
library(DropletUtils)
library(ggplot2)
library(EnsDb.Mmusculus.v79)
library(scuttle)
library(scater)
library(scran)
library(scDblFinder)
sce <- WTChimeraData(samples = 5, type = "raw")
sce <- sce[[1]]
sce
OUTPUT
class: SingleCellExperiment
dim: 29453 522554
metadata(0):
assays(1): counts
rownames(29453): ENSMUSG00000051951 ENSMUSG00000089699 ...
ENSMUSG00000095742 tomato-td
rowData names(2): ENSEMBL SYMBOL
colnames(522554): AAACCTGAGAAACCAT AAACCTGAGAAACCGC ...
TTTGTCATCTTTACGT TTTGTCATCTTTCCTC
colData names(0):
reducedDimNames(0):
mainExpName: NULL
altExpNames(0):This is the same data we examined in the previous lesson.
Droplet processing
From the experiment, we expect to have only a few thousand cells, while we can see that we have data for more than 500,000 droplets. It is likely that most of these droplets are empty and are capturing only ambient or background RNA.
Callout
Depending on your data source, identifying and discarding empty droplets may not be necessary. Some academic institutions have research cores dedicated to single cell work that perform the sample preparation and sequencing. Many of these cores will also perform empty droplet filtering and other initial QC steps. Specific details on the steps in common pipelines like 10x Genomics’ CellRanger can usually be found in the documentation that came with the sequencing material.
The main point is: if the sequencing outputs were provided to you by someone else, make sure to communicate with them about what pre-processing steps have been performed, if any.
We can visualize barcode read totals to visualize the distinction between empty droplets and properly profiled single cells in a so-called “knee plot”:
R
bcrank <- barcodeRanks(counts(sce))
# Only showing unique points for plotting speed.
uniq <- !duplicated(bcrank$rank)
line_df <- data.frame(cutoff = names(metadata(bcrank)),
value = unlist(metadata(bcrank)))
ggplot(bcrank[uniq,], aes(rank, total)) +
geom_point() +
geom_hline(data = line_df,
aes(color = cutoff,
yintercept = value),
lty = 2) +
scale_x_log10() +
scale_y_log10() +
labs(y = "Total UMI count")
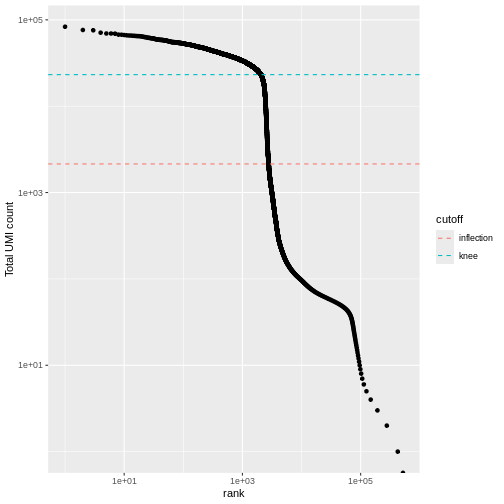
The distribution of total counts (called the unique molecular identifier or UMI count) exhibits a sharp transition between barcodes with large and small total counts, probably corresponding to cell-containing and empty droplets respectively.
A simple approach would be to apply a threshold on the total count to only retain those barcodes with large totals. However, this may unnecessarily discard libraries derived from cell types with low RNA content.
Challenge
What is the median number of total counts in the raw data?
R
median(bcrank$total)
OUTPUT
[1] 2Just 2! Clearly many barcodes produce practically no output.
Testing for empty droplets
A better approach is to test whether the expression profile for each cell barcode is significantly different from the ambient RNA pool1. Any significant deviation indicates that the barcode corresponds to a cell-containing droplet. This allows us to discriminate between well-sequenced empty droplets and droplets derived from cells with little RNA, both of which would have similar total counts.
We call cells at a false discovery rate (FDR) of 0.1%, meaning that no more than 0.1% of our called barcodes should be empty droplets on average.
R
# emptyDrops performs Monte Carlo simulations to compute p-values,
# so we need to set the seed to obtain reproducible results.
set.seed(100)
# this may take a few minutes
e.out <- emptyDrops(counts(sce))
summary(e.out$FDR <= 0.001)
OUTPUT
Mode FALSE TRUE NA's
logical 6184 3131 513239 R
sce <- sce[,which(e.out$FDR <= 0.001)]
sce
OUTPUT
class: SingleCellExperiment
dim: 29453 3131
metadata(0):
assays(1): counts
rownames(29453): ENSMUSG00000051951 ENSMUSG00000089699 ...
ENSMUSG00000095742 tomato-td
rowData names(2): ENSEMBL SYMBOL
colnames(3131): AAACCTGAGACTGTAA AAACCTGAGATGCCTT ... TTTGTCAGTCTGATTG
TTTGTCATCTGAGTGT
colData names(0):
reducedDimNames(0):
mainExpName: NULL
altExpNames(0):The result confirms our expectation: only 3,131 droplets contain a cell, while the large majority of droplets are empty.
Whenever your code involves the generation of random numbers, it’s a
good practice to set the random seed in R with
set.seed().
Setting the seed to a specific value (in the above example to 100) will cause the pseudo-random number generator to return the same pseudo-random numbers in the same order.
This allows us to write code with reproducible results, despite technically involving the generation of (pseudo-)random numbers.
Quality control
While we have removed empty droplets, this does not necessarily imply that all the cell-containing droplets should be kept for downstream analysis. In fact, some droplets could contain low-quality samples, due to cell damage or failure in library preparation.
Retaining these low-quality samples in the analysis could be problematic as they could:
- form their own cluster, complicating the interpretation of the results
- interfere with variance estimation and principal component analysis
- contain contaminating transcripts from ambient RNA
To mitigate these problems, we can check a few quality control (QC) metrics and, if needed, remove low-quality samples.
Choice of quality control metrics
There are many possible ways to define a set of quality control metrics, see for instance Cole 2019. Here, we keep it simple and consider only:
- the library size, defined as the total sum of counts across all relevant features for each cell;
- the number of expressed features in each cell, defined as the number of endogenous genes with non-zero counts for that cell;
- the proportion of reads mapped to genes in the mitochondrial genome.
In particular, high proportions of mitochondrial genes are indicative of poor-quality cells, presumably because of loss of cytoplasmic RNA from perforated cells. The reasoning is that, in the presence of modest damage, the holes in the cell membrane permit efflux of individual transcript molecules but are too small to allow mitochondria to escape, leading to a relative enrichment of mitochondrial transcripts. For single-nucleus RNA-seq experiments, high proportions are also useful as they can mark cells where the cytoplasm has not been successfully stripped.
First, we need to identify mitochondrial genes. We use the available
EnsDb mouse package available in Bioconductor, but a more
updated version of Ensembl can be used through the
AnnotationHub or biomaRt packages.
R
chr.loc <- mapIds(EnsDb.Mmusculus.v79,
keys = rownames(sce),
keytype = "GENEID",
column = "SEQNAME")
is.mito <- which(chr.loc == "MT")
We can use the scuttle package to compute a set of
quality control metrics, specifying that we want to use the
mitochondrial genes as a special set of features.
R
df <- perCellQCMetrics(sce, subsets = list(Mito = is.mito))
colData(sce) <- cbind(colData(sce), df)
colData(sce)
OUTPUT
DataFrame with 3131 rows and 6 columns
sum detected subsets_Mito_sum subsets_Mito_detected
<numeric> <integer> <numeric> <integer>
AAACCTGAGACTGTAA 27577 5418 471 10
AAACCTGAGATGCCTT 29309 5405 679 10
AAACCTGAGCAGCCTC 28795 5218 480 12
AAACCTGCATACTCTT 34794 4781 496 12
AAACCTGGTGGTACAG 262 229 0 0
... ... ... ... ...
TTTGGTTTCGCCATAA 38398 6020 252 12
TTTGTCACACCCTATC 3013 1451 123 9
TTTGTCACATTCTCAT 1472 675 599 11
TTTGTCAGTCTGATTG 361 293 0 0
TTTGTCATCTGAGTGT 267 233 16 6
subsets_Mito_percent total
<numeric> <numeric>
AAACCTGAGACTGTAA 1.70795 27577
AAACCTGAGATGCCTT 2.31669 29309
AAACCTGAGCAGCCTC 1.66696 28795
AAACCTGCATACTCTT 1.42553 34794
AAACCTGGTGGTACAG 0.00000 262
... ... ...
TTTGGTTTCGCCATAA 0.656284 38398
TTTGTCACACCCTATC 4.082310 3013
TTTGTCACATTCTCAT 40.692935 1472
TTTGTCAGTCTGATTG 0.000000 361
TTTGTCATCTGAGTGT 5.992509 267Now that we have computed the metrics, we have to decide on thresholds to define high- and low-quality samples. We could check how many cells are above/below a certain fixed threshold. For instance,
R
table(df$sum < 10000)
OUTPUT
FALSE TRUE
2477 654 R
table(df$subsets_Mito_percent > 10)
OUTPUT
FALSE TRUE
2761 370 or we could look at the distribution of such metrics and use a data adaptive threshold.
R
summary(df$detected)
OUTPUT
Min. 1st Qu. Median Mean 3rd Qu. Max.
98 4126 5168 4455 5670 7908 R
summary(df$subsets_Mito_percent)
OUTPUT
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.000 1.155 1.608 5.079 2.182 66.968 We can use the perCellQCFilters function to apply a set
of common adaptive filters to identify low-quality cells. By default, we
consider a value to be an outlier if it is more than 3 median absolute
deviations (MADs) from the median in the “problematic” direction. This
is loosely motivated by the fact that such a filter will retain 99% of
non-outlier values that follow a normal distribution.
R
reasons <- perCellQCFilters(df, sub.fields = "subsets_Mito_percent")
reasons
OUTPUT
DataFrame with 3131 rows and 4 columns
low_lib_size low_n_features high_subsets_Mito_percent discard
<outlier.filter> <outlier.filter> <outlier.filter> <logical>
1 FALSE FALSE FALSE FALSE
2 FALSE FALSE FALSE FALSE
3 FALSE FALSE FALSE FALSE
4 FALSE FALSE FALSE FALSE
5 TRUE TRUE FALSE TRUE
... ... ... ... ...
3127 FALSE FALSE FALSE FALSE
3128 TRUE TRUE TRUE TRUE
3129 TRUE TRUE TRUE TRUE
3130 TRUE TRUE FALSE TRUE
3131 TRUE TRUE TRUE TRUER
sce$discard <- reasons$discard
Challenge
Maybe our sample preparation was poor and we want the QC to be more strict. How could we change the set the QC filtering to use 2.5 MADs as the threshold for outlier calling?
You set nmads = 2.5 like so:
R
reasons_strict <- perCellQCFilters(df, sub.fields = "subsets_Mito_percent", nmads = 2.5)
You would then need to reassign the discard column as
well, but we’ll stick with the 3 MADs default for now.
Diagnostic plots
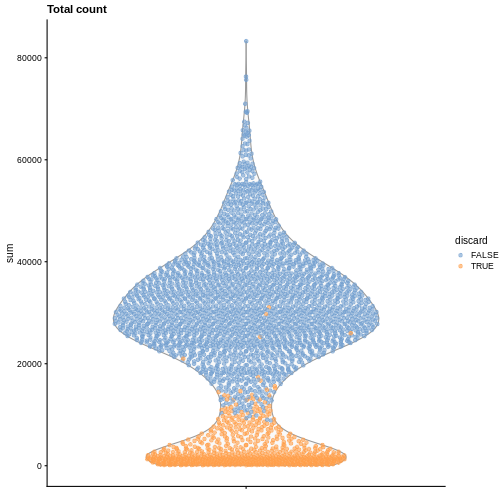
It is always a good idea to check the distribution of the QC metrics and to visualize the cells that were removed, to identify possible problems with the procedure. In particular, we expect to have few outliers and with a marked difference from “regular” cells (e.g., a bimodal distribution or a long tail). Moreover, if there are too many discarded cells, further exploration might be needed.
R
plotColData(sce, y = "sum", colour_by = "discard") +
labs(title = "Total count")
R
plotColData(sce, y = "detected", colour_by = "discard") +
labs(title = "Detected features")
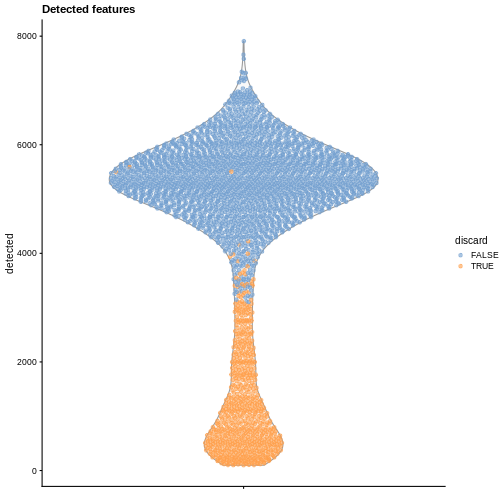
R
plotColData(sce, y = "subsets_Mito_percent", colour_by = "discard") +
labs(title = "Mito percent")
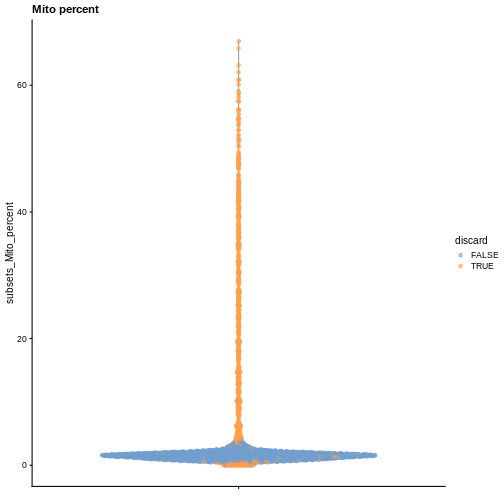
While the univariate distribution of QC metrics can give some insight on the quality of the sample, often looking at the bivariate distribution of QC metrics is useful, e.g., to confirm that there are no cells with both large total counts and large mitochondrial counts, to ensure that we are not inadvertently removing high-quality cells that happen to be highly metabolically active.
R
plotColData(sce, x ="sum", y = "subsets_Mito_percent", colour_by = "discard")
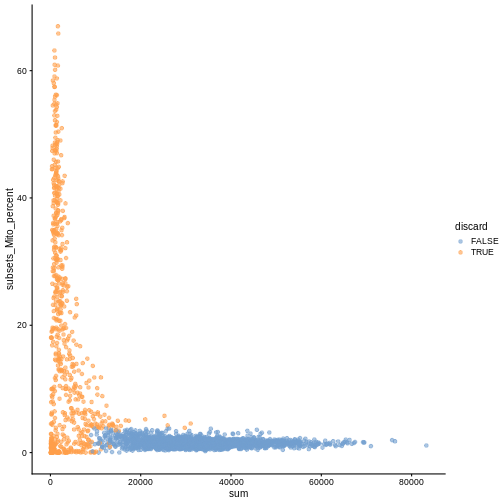
It could also be a good idea to perform a differential expression analysis between retained and discarded cells to check wether we are removing an unusual cell population rather than low-quality libraries (see Section 1.5 of OSCA advanced).
Once we are happy with the results, we can discard the low-quality cells by subsetting the original object.
R
sce <- sce[,!sce$discard]
sce
OUTPUT
class: SingleCellExperiment
dim: 29453 2437
metadata(0):
assays(1): counts
rownames(29453): ENSMUSG00000051951 ENSMUSG00000089699 ...
ENSMUSG00000095742 tomato-td
rowData names(2): ENSEMBL SYMBOL
colnames(2437): AAACCTGAGACTGTAA AAACCTGAGATGCCTT ... TTTGGTTTCAGTCAGT
TTTGGTTTCGCCATAA
colData names(7): sum detected ... total discard
reducedDimNames(0):
mainExpName: NULL
altExpNames(0):Normalization
Systematic differences in sequencing coverage between libraries are often observed in single-cell RNA sequencing data. They typically arise from technical differences in cDNA capture or PCR amplification efficiency across cells, attributable to the difficulty of achieving consistent library preparation with minimal starting material2. Normalization aims to remove these differences such that they do not interfere with comparisons of the expression profiles between cells. The hope is that the observed heterogeneity or differential expression within the cell population are driven by biology and not technical biases.
We will mostly focus our attention on scaling normalization, which is the simplest and most commonly used class of normalization strategies. This involves dividing all counts for each cell by a cell-specific scaling factor, often called a size factor. The assumption here is that any cell-specific bias (e.g., in capture or amplification efficiency) affects all genes equally via scaling of the expected mean count for that cell. The size factor for each cell represents the estimate of the relative bias in that cell, so division of its counts by its size factor should remove that bias. The resulting “normalized expression values” can then be used for downstream analyses such as clustering and dimensionality reduction.
The simplest and most natural strategy would be to normalize by the total sum of counts across all genes for each cell. This is often called the library size normalization.
The library size factor for each cell is directly proportional to its library size where the proportionality constant is defined such that the mean size factor across all cells is equal to 1. This ensures that the normalized expression values are on the same scale as the original counts.
R
lib.sf <- librarySizeFactors(sce)
summary(lib.sf)
OUTPUT
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.2730 0.7879 0.9600 1.0000 1.1730 2.5598 R
sf_df <- data.frame(size_factor = lib.sf)
ggplot(sf_df, aes(size_factor)) +
geom_histogram() +
scale_x_log10()
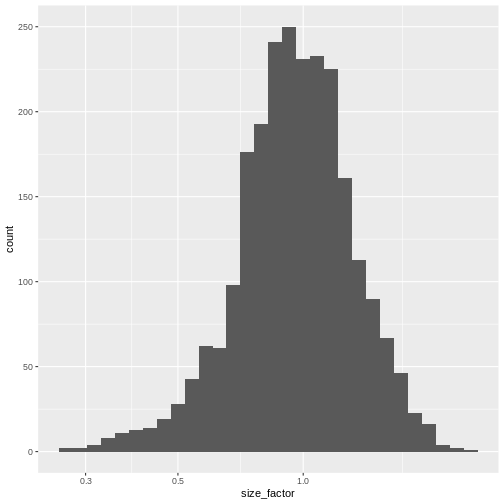
Normalization by deconvolution
Library size normalization is not optimal, as it assumes that the total sum of UMI counts differ between cells only for technical and not biological reasons. This can be a problem if a highly-expressed subset of genes is differentially expressed between cells or cell types.
Several robust normalization methods have been proposed for bulk RNA-seq. However, these methods may underperform in single-cell data due to the dominance of low and zero counts. To overcome this, one solution is to pool counts from many cells to increase the size of the counts for accurate size factor estimation3. Pool-based size factors are then deconvolved into cell-based factors for normalization of each cell’s expression profile.
We use a pre-clustering step: cells in each cluster are normalized separately and the size factors are rescaled to be comparable across clusters. This avoids the assumption that most genes are non-DE across the entire population – only a non-DE majority is required between pairs of clusters, which is a weaker assumption for highly heterogeneous populations.
Note that while we focus on normalization by deconvolution here, many other methods have been proposed and lead to similar performance (see Borella 2022 for a comparative review).
R
set.seed(100)
clust <- quickCluster(sce)
table(clust)
OUTPUT
clust
1 2 3 4 5 6 7 8 9 10 11 12 13
273 159 250 122 187 201 154 252 152 169 199 215 104 R
deconv.sf <- pooledSizeFactors(sce, cluster = clust)
summary(deconv.sf)
OUTPUT
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.3100 0.8028 0.9626 1.0000 1.1736 2.7858 R
sf_df$deconv_sf <- deconv.sf
sf_df$clust <- clust
ggplot(sf_df, aes(size_factor, deconv_sf)) +
geom_abline() +
geom_point(aes(color = clust)) +
scale_x_log10() +
scale_y_log10()
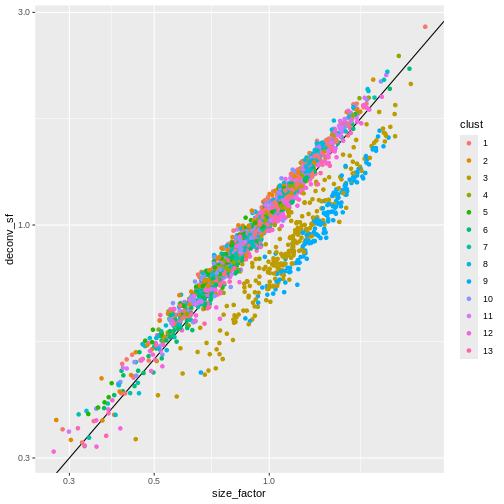
Once we have computed the size factors, we compute the normalized
expression values for each cell by dividing the count for each gene with
the appropriate size factor for that cell. Since we are typically going
to work with log-transformed counts, the function
logNormCounts also log-transforms the normalized values,
creating a new assay called logcounts.
R
sizeFactors(sce) <- deconv.sf
sce <- logNormCounts(sce)
sce
OUTPUT
class: SingleCellExperiment
dim: 29453 2437
metadata(0):
assays(2): counts logcounts
rownames(29453): ENSMUSG00000051951 ENSMUSG00000089699 ...
ENSMUSG00000095742 tomato-td
rowData names(2): ENSEMBL SYMBOL
colnames(2437): AAACCTGAGACTGTAA AAACCTGAGATGCCTT ... TTTGGTTTCAGTCAGT
TTTGGTTTCGCCATAA
colData names(8): sum detected ... discard sizeFactor
reducedDimNames(0):
mainExpName: NULL
altExpNames(0):R
lib.sf <- librarySizeFactors(sce)
sizeFactors(sce) <- lib.sf
sce <- logNormCounts(sce)
sce
If you run this chunk, make sure to go back and re-run the normalization with deconvolution normalization if you want your work to align with the rest of this episode.
Feature Selection
The typical next steps in the analysis of single-cell data are dimensionality reduction and clustering, which involve measuring the similarity between cells.
The choice of genes to use in this calculation has a major impact on the results. We want to select genes that contain useful information about the biology of the system while removing genes that contain only random noise. This aims to preserve interesting biological structure without the variance that obscures that structure, and to reduce the size of the data to improve computational efficiency of later steps.
Quantifying per-gene variation
The simplest approach to feature selection is to select the most variable genes based on their log-normalized expression across the population. This is motivated by practical idea that if we’re going to try to explain variation in gene expression by biological factors, those genes need to have variance to explain.
Calculation of the per-gene variance is simple but feature selection
requires modeling of the mean-variance relationship. The
log-transformation is not a variance stabilizing transformation in most
cases, which means that the total variance of a gene is driven more by
its abundance than its underlying biological heterogeneity. To account
for this, the modelGeneVar function fits a trend to the
variance with respect to abundance across all genes.
R
dec.sce <- modelGeneVar(sce)
fit.sce <- metadata(dec.sce)
mean_var_df <- data.frame(mean = fit.sce$mean,
var = fit.sce$var)
ggplot(mean_var_df, aes(mean, var)) +
geom_point() +
geom_function(fun = fit.sce$trend,
color = "dodgerblue") +
labs(x = "Mean of log-expression",
y = "Variance of log-expression")
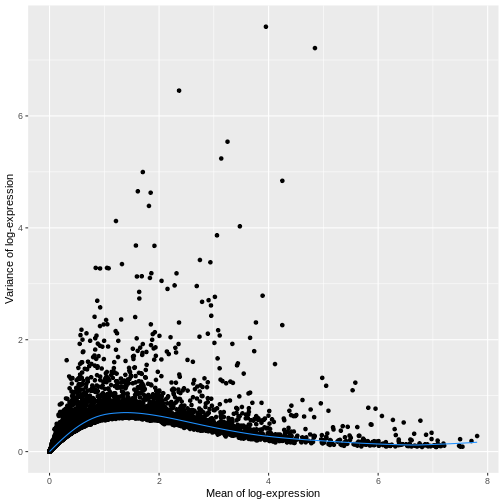
The blue line represents the uninteresting “technical” variance for any given gene abundance. The genes with a lot of additional variance exhibit interesting “biological” variation.
Selecting highly variable genes
The next step is to select the subset of HVGs to use in downstream
analyses. A larger set will assure that we do not remove important
genes, at the cost of potentially increasing noise. Typically, we
restrict ourselves to the top \(n\)
genes, here we chose \(n = 1000\), but
this choice should be guided by prior biological knowledge; for
instance, we may expect that only about 10% of genes to be
differentially expressed across our cell populations and hence select
10% of genes as highly variable (e.g., by setting
prop = 0.1).
R
hvg.sce.var <- getTopHVGs(dec.sce, n = 1000)
head(hvg.sce.var)
OUTPUT
[1] "ENSMUSG00000055609" "ENSMUSG00000052217" "ENSMUSG00000069919"
[4] "ENSMUSG00000052187" "ENSMUSG00000048583" "ENSMUSG00000051855"Challenge
Imagine you have data that were prepared by three people with varying level of experience, which leads to varying technical noise. How can you account for this blocking structure when selecting HVGs?
modelGeneVar() can take a block
argument.
Use the block argument in the call to
modelGeneVar() like so. We don’t have experimenter
information in this dataset, so in order to have some names to work with
we assign them randomly from a set of names.
R
sce$experimenter = factor(sample(c("Perry", "Merry", "Gary"),
replace = TRUE,
size = ncol(sce)))
blocked_variance_df = modelGeneVar(sce,
block = sce$experimenter)
Blocked models are evaluated on each block separately then combined.
If the experimental groups are related in some structured way, it may be
preferable to use the design argument. See
?modelGeneVar for more detail.
Dimensionality Reduction
Many scRNA-seq analysis procedures involve comparing cells based on their expression values across multiple genes. For example, clustering aims to identify cells with similar transcriptomic profiles by computing Euclidean distances across genes. In these applications, each individual gene represents a dimension of the data, hence we can think of the data as “living” in a ten-thousand-dimensional space.
As the name suggests, dimensionality reduction aims to reduce the number of dimensions, while preserving as much as possible of the original information. This obviously reduces the computational work (e.g., it is easier to compute distance in lower-dimensional spaces), and more importantly leads to less noisy and more interpretable results (cf. the curse of dimensionality).
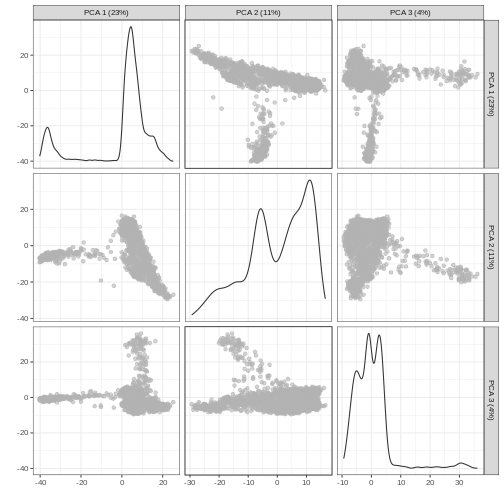
Principal Component Analysis (PCA)
Principal component analysis (PCA) is a dimensionality reduction technique that provides a parsimonious summarization of the data by replacing the original variables (genes) by fewer linear combinations of these variables, that are orthogonal and have successively maximal variance. Such linear combinations seek to “separate out” the observations (cells), while losing as little information as possible.
Without getting into the technical details, one nice feature of PCA is that the principal components (PCs) are ordered by how much variance of the original data they “explain”. Furthermore, by focusing on the top \(k\) PC we are focusing on the most important directions of variability, which hopefully correspond to biological rather than technical variance. (It is however good practice to check this by e.g. looking at correlation between technical QC metrics and PCs).
One simple way to maximize our chance of capturing biological variation is by computing the PCs starting from the highly variable genes identified before.
R
sce <- runPCA(sce, subset_row = hvg.sce.var)
sce
OUTPUT
class: SingleCellExperiment
dim: 29453 2437
metadata(0):
assays(2): counts logcounts
rownames(29453): ENSMUSG00000051951 ENSMUSG00000089699 ...
ENSMUSG00000095742 tomato-td
rowData names(2): ENSEMBL SYMBOL
colnames(2437): AAACCTGAGACTGTAA AAACCTGAGATGCCTT ... TTTGGTTTCAGTCAGT
TTTGGTTTCGCCATAA
colData names(8): sum detected ... discard sizeFactor
reducedDimNames(1): PCA
mainExpName: NULL
altExpNames(0):By default, runPCA computes the first 50 principal
components. We can check how much original variability they explain.
These values are stored in the attributes of the percentVar
reducedDim:
R
pct_var_df <- data.frame(PC = 1:50,
pct_var = attr(reducedDim(sce), "percentVar"))
ggplot(pct_var_df,
aes(PC, pct_var)) +
geom_point() +
labs(y = "Variance explained (%)")
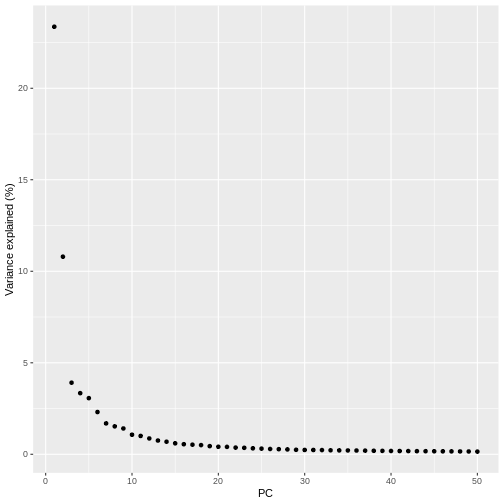
You can see the first two PCs capture the largest amount of variation, but in this case you have to take the first 8 PCs before you’ve captured 50% of the total.
And we can of course visualize the first 2-3 components, perhaps color-coding each point by an interesting feature, in this case the total number of UMIs per cell.
R
plotPCA(sce, colour_by = "sum")
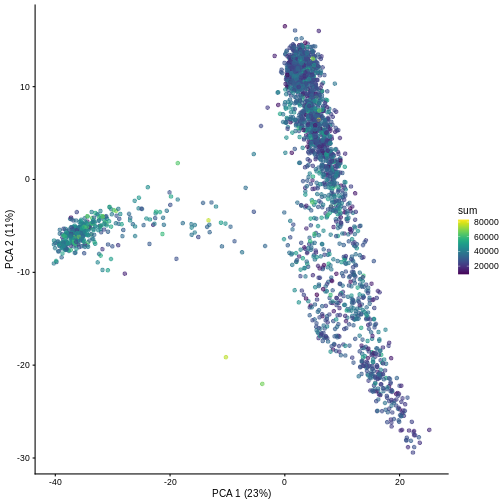
It can be helpful to compare pairs of PCs. This can be done with the
ncomponents argument to plotReducedDim(). For
example if one batch or cell type splits off on a particular PC, this
can help visualize the effect of that.
R
plotReducedDim(sce, dimred = "PCA", ncomponents = 3)
Non-linear methods
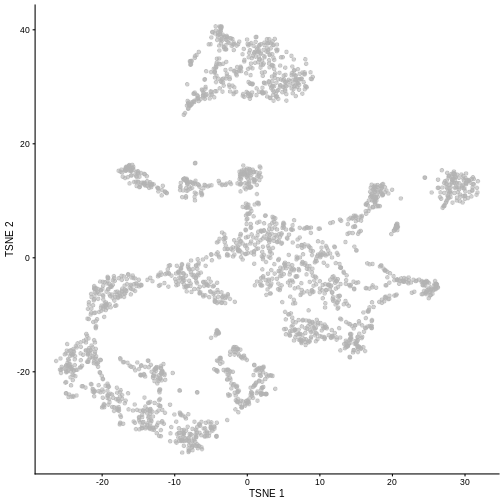
While PCA is a simple and effective way to visualize (and interpret!) scRNA-seq data, non-linear methods such as t-SNE (t-stochastic neighbor embedding) and UMAP (uniform manifold approximation and projection) have gained much popularity in the literature.
These methods attempt to find a low-dimensional representation of the data that attempt to preserve pair-wise distance and structure in high-dimensional gene space as best as possible.
R
set.seed(100)
sce <- runTSNE(sce, dimred = "PCA")
plotTSNE(sce)
R
set.seed(111)
sce <- runUMAP(sce, dimred = "PCA")
plotUMAP(sce)
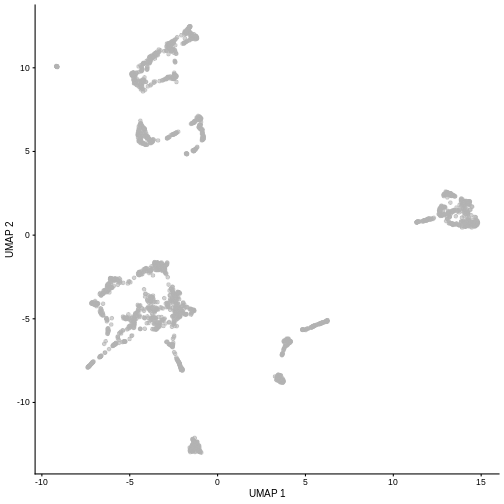
It is easy to over-interpret t-SNE and UMAP plots. We note that the relative sizes and positions of the visual clusters may be misleading, as they tend to inflate dense clusters and compress sparse ones, such that we cannot use the size as a measure of subpopulation heterogeneity.
In addition, these methods are not guaranteed to preserve the global structure of the data (e.g., the relative locations of non-neighboring clusters), such that we cannot use their positions to determine relationships between distant clusters.
Note that the sce object now includes all the computed
dimensionality reduced representations of the data for ease of reusing
and replotting without the need for recomputing. Note the added
reducedDimNames row when printing sce
here:
R
sce
OUTPUT
class: SingleCellExperiment
dim: 29453 2437
metadata(0):
assays(2): counts logcounts
rownames(29453): ENSMUSG00000051951 ENSMUSG00000089699 ...
ENSMUSG00000095742 tomato-td
rowData names(2): ENSEMBL SYMBOL
colnames(2437): AAACCTGAGACTGTAA AAACCTGAGATGCCTT ... TTTGGTTTCAGTCAGT
TTTGGTTTCGCCATAA
colData names(8): sum detected ... discard sizeFactor
reducedDimNames(3): PCA TSNE UMAP
mainExpName: NULL
altExpNames(0):Despite their shortcomings, t-SNE and UMAP can be useful visualization techniques. When using them, it is important to consider that they are stochastic methods that involve a random component (each run will lead to different plots) and that there are key parameters to be set that change the results substantially (e.g., the “perplexity” parameter of t-SNE).
Challenge
Re-run the UMAP for the same sample starting from the pre-processed
data (i.e. not type = "raw"). What looks the same? What
looks different?
R
set.seed(111)
sce5 <- WTChimeraData(samples = 5)
sce5 <- logNormCounts(sce5)
sce5 <- runPCA(sce5)
sce5 <- runUMAP(sce5)
plotUMAP(sce5)
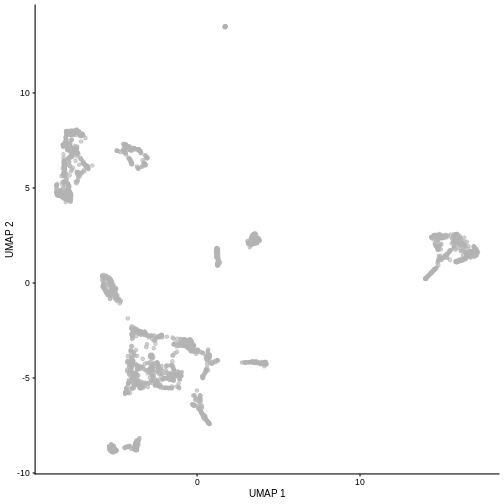
Given that it’s the same cells processed through a very similar pipeline, the result should look very similar. There’s a slight difference in the total number of cells, probably because the official processing pipeline didn’t use the exact same random seed / QC arguments as us.
But you’ll notice that even though the shape of the structures are similar, they look slightly distorted. If the upstream QC parameters change, the downstream output visualizations will also change.
Doublet identification
Doublets are artifactual libraries generated from two cells. They typically arise due to errors in cell sorting or capture. Specifically, in droplet-based protocols, it may happen that two cells are captured in the same droplet.
Doublets are obviously undesirable when the aim is to characterize populations at the single-cell level. In particular, doublets can be mistaken for intermediate populations or transitory states that do not actually exist. Thus, it is desirable to identify and remove doublet libraries so that they do not compromise interpretation of the results.
It is not easy to computationally identify doublets as they can be hard to distinguish from transient states and/or cell populations with high RNA content. When possible, it is good to rely on experimental strategies to minimize doublets, e.g., by using genetic variation (e.g., pooling multiple donors in one run) or antibody tagging (e.g., CITE-seq).
There are several computational methods to identify doublets; we describe only one here based on in-silico simulation of doublets.
Computing doublet densities
At a high level, the algorithm can be defined by the following steps:
- Simulate thousands of doublets by adding together two randomly chosen single-cell profiles.
- For each original cell, compute the density of simulated doublets in the surrounding neighborhood.
- For each original cell, compute the density of other observed cells in the neighborhood.
- Return the ratio between the two densities as a “doublet score” for each cell.
Intuitively, if a “cell” is surrounded only by simulated doublets is very likely to be a doublet itself.
This approach is implemented below using the scDblFinder
library. We then visualize the scores in a t-SNE plot.
R
set.seed(100)
dbl.dens <- computeDoubletDensity(sce, subset.row = hvg.sce.var,
d = ncol(reducedDim(sce)))
summary(dbl.dens)
OUTPUT
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.04874 0.28757 0.46790 0.65614 0.82371 14.88032 R
sce$DoubletScore <- dbl.dens
plotTSNE(sce, colour_by = "DoubletScore")
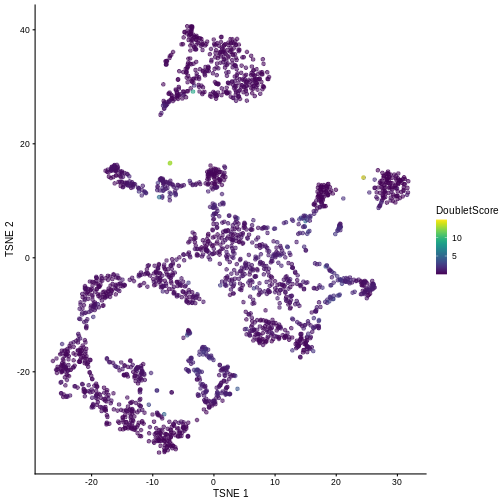
We can explicitly convert this into doublet calls by identifying large outliers for the score within each sample. Here we use the “griffiths” method to do so.
R
dbl.calls <- doubletThresholding(data.frame(score = dbl.dens),
method = "griffiths",
returnType = "call")
summary(dbl.calls)
OUTPUT
singlet doublet
2124 313 R
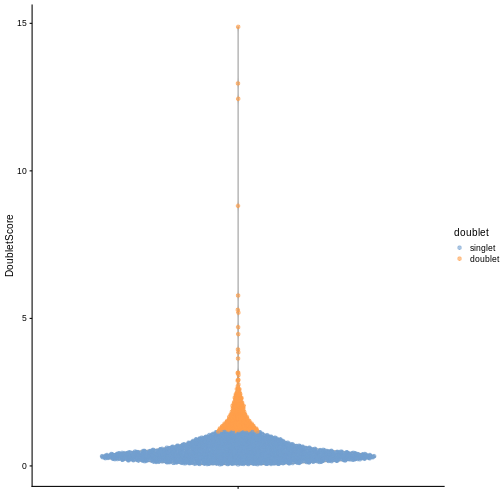
sce$doublet <- dbl.calls
plotColData(sce, y = "DoubletScore", colour_by = "doublet")
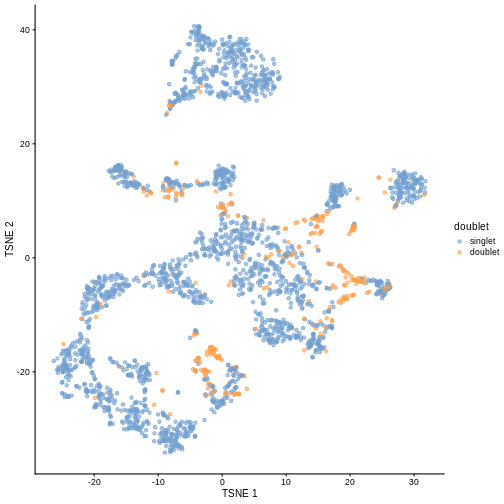
R
plotTSNE(sce, colour_by = "doublet")
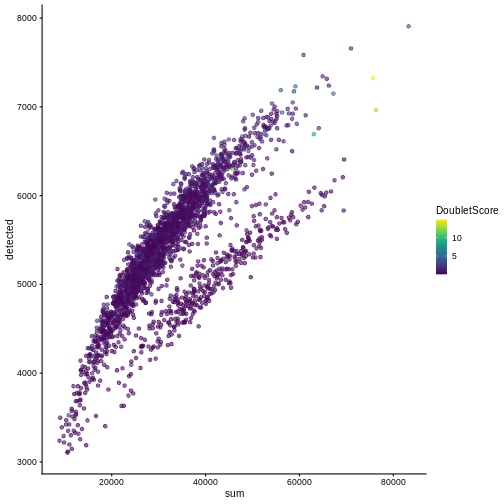
One way to determine whether a cell is in a real transient state or it is a doublet is to check the number of detected genes and total UMI counts.
R
plotColData(sce, "detected", "sum", colour_by = "DoubletScore")
R
plotColData(sce, "detected", "sum", colour_by = "doublet")
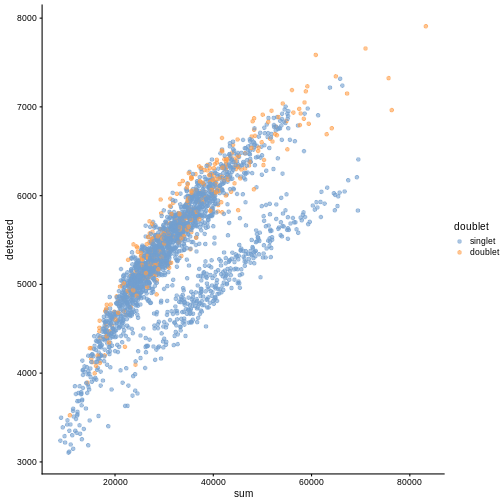
In this case, we only have a few doublets at the periphery of some clusters. It could be fine to keep the doublets in the analysis, but it may be safer to discard them to avoid biases in downstream analysis (e.g., differential expression).
Exercises
Exercise 1: Normalization
Here we used the deconvolution method implemented in
scran based on a previous clustering step. Use the
pooledSizeFactors to compute the size factors without
considering a preliminary clustering. Compare the resulting size factors
via a scatter plot. How do the results change? What are the risks of not
including clustering information?
R
deconv.sf2 <- pooledSizeFactors(sce) # dropped `cluster = clust` here
summary(deconv.sf2)
OUTPUT
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.2985 0.8142 0.9583 1.0000 1.1582 2.7054 R
sf_df$deconv_sf2 <- deconv.sf2
sf_df$clust <- clust
ggplot(sf_df, aes(deconv_sf, deconv_sf2)) +
geom_abline() +
geom_point(aes(color = clust)) +
scale_x_log10() +
scale_y_log10() +
facet_wrap(vars(clust))
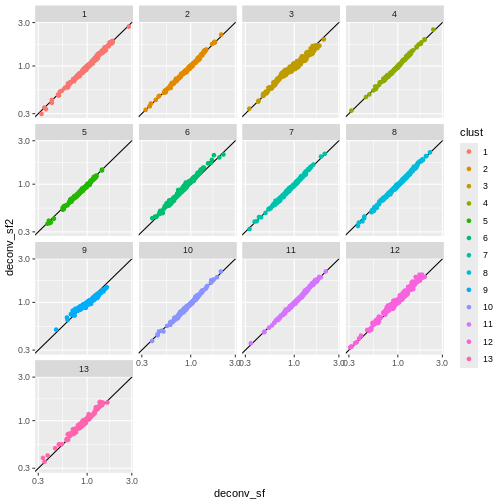
You can see that we get largely similar results, though for clusters
3 and 9 there’s a slight deviation from the y=x
relationship because these clusters (which are fairly distinct from the
other clusters) are now being pooled with cells from other clusters.
This slightly violates the “majority non-DE genes” assumption.
Exercise 2: PBMC Data
The DropletTestFiles
package includes the raw output from Cell Ranger of the peripheral
blood mononuclear cell (PBMC) dataset from 10X Genomics, publicly
available from the 10X Genomics website. Repeat the analysis of this
vignette using those data.
The hint demonstrates how to identify, download, extract, and read
the data starting from the help documentation of
?DropletTestFiles::listTestFiles, but try working through
those steps on your own for extra challenge (they’re useful skills to
develop in practice).
R
library(DropletTestFiles)
set.seed(100)
listTestFiles(dataset = "tenx-3.1.0-5k_pbmc_protein_v3") # look up the remote data path of the raw data
raw_rdatapath <- "DropletTestFiles/tenx-3.1.0-5k_pbmc_protein_v3/1.0.0/raw.tar.gz"
local_path <- getTestFile(raw_rdatapath, prefix = FALSE)
file.copy(local_path,
paste0(local_path, ".tar.gz"))
untar(paste0(local_path, ".tar.gz"),
exdir = dirname(local_path))
sce <- read10xCounts(file.path(dirname(local_path), "raw_feature_bc_matrix/"))
After getting the data, the steps are largely copy-pasted from above. For the sake of simplicity the mitochondrial genes are identified by gene symbols in the row data. Otherwise the steps are the same:
R
e.out <- emptyDrops(counts(sce))
sce <- sce[,which(e.out$FDR <= 0.001)]
# Thankfully the data come with gene symbols, which we can use to identify mitochondrial genes:
is.mito <- grepl("^MT-", rowData(sce)$Symbol)
# QC metrics ----
df <- perCellQCMetrics(sce, subsets = list(Mito = is.mito))
colData(sce) <- cbind(colData(sce), df)
colData(sce)
reasons <- perCellQCFilters(df, sub.fields = "subsets_Mito_percent")
reasons
sce$discard <- reasons$discard
sce <- sce[,!sce$discard]
# Normalization ----
clust <- quickCluster(sce)
table(clust)
deconv.sf <- pooledSizeFactors(sce, cluster = clust)
sizeFactors(sce) <- deconv.sf
sce <- logNormCounts(sce)
# Feature selection ----
dec.sce <- modelGeneVar(sce)
hvg.sce.var <- getTopHVGs(dec.sce, n = 1000)
# Dimensionality reduction ----
sce <- runPCA(sce, subset_row = hvg.sce.var)
sce <- runTSNE(sce, dimred = "PCA")
sce <- runUMAP(sce, dimred = "PCA")
# Doublet finding ----
dbl.dens <- computeDoubletDensity(sce, subset.row = hvg.sce.var,
d = ncol(reducedDim(sce)))
sce$DoubletScore <- dbl.dens
dbl.calls <- doubletThresholding(data.frame(score = dbl.dens),
method = "griffiths",
returnType = "call")
sce$doublet <- dbl.calls
Extension challenge 1: Spike-ins
Some sophisticated experiments perform additional steps so that they can estimate size factors from so-called “spike-ins”. Judging by the name, what do you think “spike-ins” are, and what additional steps are required to use them?
Spike-ins are deliberately-introduced exogeneous RNA from an exotic or synthetic source at a known concentration. This provides a known signal to normalize against. Exotic (e.g. soil bacteria RNA in a study of human cells) or synthetic RNA is used in order to avoid confusing spike-in RNA with sample RNA. This has the obvious advantage of accounting for cell-wise variation, but can substantially increase the amount of sample-preparation work.
Extension challenge 2: Background research
Run an internet search for some of the most highly variable genes we identified in the feature selection section. See if you can identify the type of protein they produce or what sort of process they’re involved in. Do they make biological sense to you?
Extension challenge 3: Reduced dimensionality representations
Can dimensionality reduction techniques provide a perfectly accurate representation of the data?
Mathematically, this would require the data to fall on a two-dimensional plane (for linear methods like PCA) or a smooth 2D manifold (for methods like UMAP). You can be confident that this will never happen in real-world data, so the reduction from ~2500-dimensional gene space to two-dimensional plot space always involves some degree of information loss.
Key Points
- Empty droplets, i.e. droplets that do not contain intact cells and
that capture only ambient or background RNA, should be removed prior to
an analysis. The
emptyDropsfunction from the DropletUtils package can be used to identify empty droplets. - Doublets, i.e. instances where two cells are captured in the same
droplet, should also be removed prior to an analysis. The
computeDoubletDensityanddoubletThresholdingfunctions from the scDblFinder package can be used to identify doublets. - Quality control (QC) uses metrics such as library size, number of expressed features, and mitochondrial read proportion, based on which low-quality cells can be detected and filtered out. Diagnostic plots of the chosen QC metrics are important to identify possible issues.
- Normalization is required to account for systematic differences in sequencing coverage between libraries and to make measurements comparable between cells. Library size normalization is the most commonly used normalization strategy, and involves dividing all counts for each cell by a cell-specific scaling factor.
- Feature selection aims at selecting genes that contain useful
information about the biology of the system while removing genes that
contain only random noise. Calculate per-gene variance with the
modelGeneVarfunction and select highly-variable genes withgetTopHVGs. - Dimensionality reduction aims at reducing the computational work and at obtaining less noisy and more interpretable results. PCA is a simple and effective linear dimensionality reduction technique that provides interpretable results for further analysis such as clustering of cells. Non-linear approaches such as UMAP and t-SNE can be useful for visualization, but the resulting representations should not be used in downstream analysis.
Further Reading
- OSCA book, Basics, Chapters 1-4
- OSCA book, Advanced, Chapters 7-8
Session Info
R
sessionInfo()
OUTPUT
R version 4.4.1 (2024-06-14)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 22.04.5 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.10.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.10.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
time zone: UTC
tzcode source: system (glibc)
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] scDblFinder_1.18.0 scran_1.32.0
[3] scater_1.32.0 scuttle_1.14.0
[5] EnsDb.Mmusculus.v79_2.99.0 ensembldb_2.28.0
[7] AnnotationFilter_1.28.0 GenomicFeatures_1.56.0
[9] AnnotationDbi_1.66.0 ggplot2_3.5.1
[11] DropletUtils_1.24.0 MouseGastrulationData_1.18.0
[13] SpatialExperiment_1.14.0 SingleCellExperiment_1.26.0
[15] SummarizedExperiment_1.34.0 Biobase_2.64.0
[17] GenomicRanges_1.56.0 GenomeInfoDb_1.40.1
[19] IRanges_2.38.0 S4Vectors_0.42.0
[21] BiocGenerics_0.50.0 MatrixGenerics_1.16.0
[23] matrixStats_1.3.0 BiocStyle_2.32.0
loaded via a namespace (and not attached):
[1] jsonlite_1.8.8 magrittr_2.0.3
[3] ggbeeswarm_0.7.2 magick_2.8.3
[5] farver_2.1.2 rmarkdown_2.27
[7] BiocIO_1.14.0 zlibbioc_1.50.0
[9] vctrs_0.6.5 memoise_2.0.1
[11] Rsamtools_2.20.0 DelayedMatrixStats_1.26.0
[13] RCurl_1.98-1.14 htmltools_0.5.8.1
[15] S4Arrays_1.4.1 AnnotationHub_3.12.0
[17] curl_5.2.1 BiocNeighbors_1.22.0
[19] xgboost_1.7.7.1 Rhdf5lib_1.26.0
[21] SparseArray_1.4.8 rhdf5_2.48.0
[23] cachem_1.1.0 GenomicAlignments_1.40.0
[25] igraph_2.0.3 mime_0.12
[27] lifecycle_1.0.4 pkgconfig_2.0.3
[29] rsvd_1.0.5 Matrix_1.7-0
[31] R6_2.5.1 fastmap_1.2.0
[33] GenomeInfoDbData_1.2.12 digest_0.6.35
[35] colorspace_2.1-0 dqrng_0.4.1
[37] irlba_2.3.5.1 ExperimentHub_2.12.0
[39] RSQLite_2.3.7 beachmat_2.20.0
[41] labeling_0.4.3 filelock_1.0.3
[43] fansi_1.0.6 httr_1.4.7
[45] abind_1.4-5 compiler_4.4.1
[47] bit64_4.0.5 withr_3.0.0
[49] BiocParallel_1.38.0 viridis_0.6.5
[51] DBI_1.2.3 highr_0.11
[53] HDF5Array_1.32.0 R.utils_2.12.3
[55] MASS_7.3-60.2 rappdirs_0.3.3
[57] DelayedArray_0.30.1 bluster_1.14.0
[59] rjson_0.2.21 tools_4.4.1
[61] vipor_0.4.7 beeswarm_0.4.0
[63] R.oo_1.26.0 glue_1.7.0
[65] restfulr_0.0.15 rhdf5filters_1.16.0
[67] grid_4.4.1 Rtsne_0.17
[69] cluster_2.1.6 generics_0.1.3
[71] gtable_0.3.5 R.methodsS3_1.8.2
[73] data.table_1.15.4 metapod_1.12.0
[75] BiocSingular_1.20.0 ScaledMatrix_1.12.0
[77] utf8_1.2.4 XVector_0.44.0
[79] ggrepel_0.9.5 BiocVersion_3.19.1
[81] pillar_1.9.0 limma_3.60.2
[83] BumpyMatrix_1.12.0 dplyr_1.1.4
[85] BiocFileCache_2.12.0 lattice_0.22-6
[87] FNN_1.1.4 renv_1.0.11
[89] rtracklayer_1.64.0 bit_4.0.5
[91] tidyselect_1.2.1 locfit_1.5-9.9
[93] Biostrings_2.72.1 knitr_1.47
[95] gridExtra_2.3 ProtGenerics_1.36.0
[97] edgeR_4.2.0 xfun_0.44
[99] statmod_1.5.0 UCSC.utils_1.0.0
[101] lazyeval_0.2.2 yaml_2.3.8
[103] evaluate_0.23 codetools_0.2-20
[105] tibble_3.2.1 BiocManager_1.30.23
[107] cli_3.6.2 uwot_0.2.2
[109] munsell_0.5.1 Rcpp_1.0.12
[111] dbplyr_2.5.0 png_0.1-8
[113] XML_3.99-0.16.1 parallel_4.4.1
[115] blob_1.2.4 sparseMatrixStats_1.16.0
[117] bitops_1.0-7 viridisLite_0.4.2
[119] scales_1.3.0 purrr_1.0.2
[121] crayon_1.5.2 rlang_1.1.3
[123] formatR_1.14 cowplot_1.1.3
[125] KEGGREST_1.44.0 Content from Cell type annotation
Last updated on 2024-11-11 | Edit this page
Overview
Questions
- How can we identify groups of cells with similar expression profiles?
- How can we identify genes that drive separation between these groups of cells?
- How to leverage reference datasets and known marker genes for the cell type annotation of new datasets?
Objectives
- Identify groups of cells by clustering cells based on gene expression patterns.
- Identify marker genes through testing for differential expression between clusters.
- Annotate cell types through annotation transfer from reference datasets.
- Annotate cell types through marker gene set enrichment testing.
Setup
Again we’ll start by loading the libraries we’ll be using:
R
library(AUCell)
library(MouseGastrulationData)
library(SingleR)
library(bluster)
library(scater)
library(scran)
library(pheatmap)
library(GSEABase)
Data retrieval
We’ll be using the fifth processed sample from the WT chimeric mouse embryo data:
R
sce <- WTChimeraData(samples = 5, type = "processed")
sce
OUTPUT
class: SingleCellExperiment
dim: 29453 2411
metadata(0):
assays(1): counts
rownames(29453): ENSMUSG00000051951 ENSMUSG00000089699 ...
ENSMUSG00000095742 tomato-td
rowData names(2): ENSEMBL SYMBOL
colnames(2411): cell_9769 cell_9770 ... cell_12178 cell_12179
colData names(11): cell barcode ... doub.density sizeFactor
reducedDimNames(2): pca.corrected.E7.5 pca.corrected.E8.5
mainExpName: NULL
altExpNames(0):To speed up the computations, we take a random subset of 1,000 cells.
R
set.seed(123)
ind <- sample(ncol(sce), 1000)
sce <- sce[,ind]
Preprocessing
The SCE object needs to contain log-normalized expression counts as well as PCA coordinates in the reduced dimensions, so we compute those here:
R
sce <- logNormCounts(sce)
sce <- runPCA(sce)
Clustering
Clustering is an unsupervised learning procedure that is used to empirically define groups of cells with similar expression profiles. Its primary purpose is to summarize complex scRNA-seq data into a digestible format for human interpretation. This allows us to describe population heterogeneity in terms of discrete labels that are easily understood, rather than attempting to comprehend the high-dimensional manifold on which the cells truly reside. After annotation based on marker genes, the clusters can be treated as proxies for more abstract biological concepts such as cell types or states.
Graph-based clustering is a flexible and scalable technique for identifying coherent groups of cells in large scRNA-seq datasets. We first build a graph where each node is a cell that is connected to its nearest neighbors in the high-dimensional space. Edges are weighted based on the similarity between the cells involved, with higher weight given to cells that are more closely related. We then apply algorithms to identify “communities” of cells that are more connected to cells in the same community than they are to cells of different communities. Each community represents a cluster that we can use for downstream interpretation.
Here, we use the clusterCells() function from the scran package to
perform graph-based clustering using the Louvain
algorithm for community detection. All calculations are performed
using the top PCs to take advantage of data compression and denoising.
This function returns a vector containing cluster assignments for each
cell in our SingleCellExperiment object. We use the
colLabels() function to assign the cluster labels as a
factor in the column data.
R
colLabels(sce) <- clusterCells(sce, use.dimred = "PCA",
BLUSPARAM = NNGraphParam(cluster.fun = "louvain"))
table(colLabels(sce))
OUTPUT
1 2 3 4 5 6 7 8 9 10 11
100 160 99 141 63 93 60 108 44 91 41 You can see we ended up with 11 clusters of varying sizes.
We can now overlay the cluster labels as color on a UMAP plot:
R
sce <- runUMAP(sce, dimred = "PCA")
plotReducedDim(sce, "UMAP", color_by = "label")
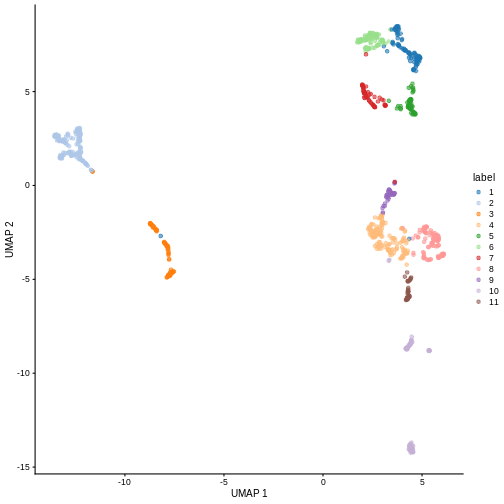
Challenge
Our clusters look semi-reasonable, but what if we wanted to make them
less granular? Look at the help documentation for
?clusterCells and ?NNGraphParam to find out
what we’d need to change to get fewer, larger clusters.
We see in the help documentation for ?clusterCells that
all of the clustering algorithm details are handled through the
BLUSPARAM argument, which needs to provide a
BlusterParam object (of which NNGraphParam is
a sub-class). Each type of clustering algorithm will have some sort of
hyper-parameter that controls the granularity of the output clusters.
Looking at ?NNGraphParam specifically, we see an argument
called k which is described as “An integer scalar
specifying the number of nearest neighbors to consider during graph
construction.” If the clustering process has to connect larger sets of
neighbors, the graph will tend to be cut into larger groups, resulting
in less granular clusters. Try the two code blocks above once more with
k = 30. Given their visual differences, do you think one
set of clusters is “right” and the other is “wrong”?
R
sce$clust2 <- clusterCells(sce, use.dimred = "PCA",
BLUSPARAM = NNGraphParam(cluster.fun = "louvain",
k = 30))
plotReducedDim(sce, "UMAP", color_by = "clust2")
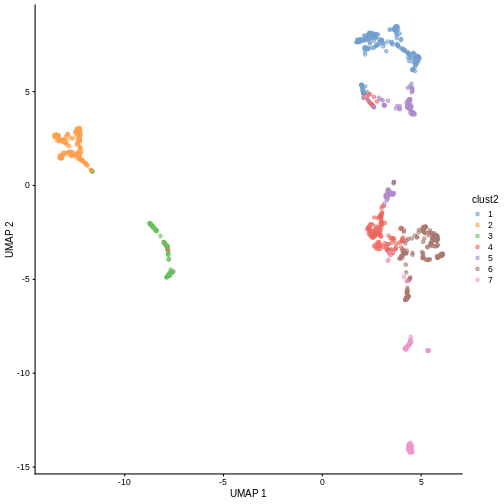
Marker gene detection
To interpret clustering results as obtained in the previous section, we identify the genes that drive separation between clusters. These marker genes allow us to assign biological meaning to each cluster based on their functional annotation. In the simplest case, we have a priori knowledge of the marker genes associated with particular cell types, allowing us to treat the clustering as a proxy for cell type identity.
The most straightforward approach to marker gene detection involves testing for differential expression between clusters. If a gene is strongly DE between clusters, it is likely to have driven the separation of cells in the clustering algorithm.
Here, we use scoreMarkers() to perform pairwise
comparisons of gene expression, focusing on up-regulated (positive)
markers in one cluster when compared to another cluster.
R
rownames(sce) <- rowData(sce)$SYMBOL
markers <- scoreMarkers(sce)
markers
OUTPUT
List of length 11
names(11): 1 2 3 4 5 6 7 8 9 10 11The resulting object contains a sorted marker gene list for each cluster, in which the top genes are those that contribute the most to the separation of that cluster from all other clusters.
Here, we inspect the ranked marker gene list for the first cluster.
R
markers[[1]]
OUTPUT
DataFrame with 29453 rows and 19 columns
self.average other.average self.detected other.detected
<numeric> <numeric> <numeric> <numeric>
Xkr4 0.0000000 0.00366101 0.00 0.00373784
Gm1992 0.0000000 0.00000000 0.00 0.00000000
Gm37381 0.0000000 0.00000000 0.00 0.00000000
Rp1 0.0000000 0.00000000 0.00 0.00000000
Sox17 0.0279547 0.18822927 0.02 0.09348375
... ... ... ... ...
AC149090.1 0.3852624 0.352021067 0.33 0.2844935
DHRSX 0.4108022 0.491424091 0.35 0.3882325
Vmn2r122 0.0000000 0.000000000 0.00 0.0000000
CAAA01147332.1 0.0164546 0.000802687 0.01 0.0010989
tomato-td 0.6341678 0.624350570 0.51 0.4808379
mean.logFC.cohen min.logFC.cohen median.logFC.cohen
<numeric> <numeric> <numeric>
Xkr4 -0.0386672 -0.208498 0.0000000
Gm1992 0.0000000 0.000000 0.0000000
Gm37381 0.0000000 0.000000 0.0000000
Rp1 0.0000000 0.000000 0.0000000
Sox17 -0.1383820 -1.292067 0.0324795
... ... ... ...
AC149090.1 0.0644403 -0.1263241 0.0366957
DHRSX -0.1154163 -0.4619613 -0.1202781
Vmn2r122 0.0000000 0.0000000 0.0000000
CAAA01147332.1 0.1338463 0.0656709 0.1414214
tomato-td 0.0220121 -0.2535145 0.0196130
max.logFC.cohen rank.logFC.cohen mean.AUC min.AUC median.AUC
<numeric> <integer> <numeric> <numeric> <numeric>
Xkr4 0.000000 6949 0.498131 0.489247 0.500000
Gm1992 0.000000 6554 0.500000 0.500000 0.500000
Gm37381 0.000000 6554 0.500000 0.500000 0.500000
Rp1 0.000000 6554 0.500000 0.500000 0.500000
Sox17 0.200319 1482 0.462912 0.228889 0.499575
... ... ... ... ... ...
AC149090.1 0.427051 1685 0.518060 0.475000 0.508779
DHRSX 0.130189 3431 0.474750 0.389878 0.471319
Vmn2r122 0.000000 6554 0.500000 0.500000 0.500000
CAAA01147332.1 0.141421 2438 0.504456 0.499560 0.505000
tomato-td 0.318068 2675 0.502868 0.427083 0.501668
max.AUC rank.AUC mean.logFC.detected min.logFC.detected
<numeric> <integer> <numeric> <numeric>
Xkr4 0.50 6882 -2.58496e-01 -1.58496e+00
Gm1992 0.50 6513 -8.00857e-17 -3.20343e-16
Gm37381 0.50 6513 -8.00857e-17 -3.20343e-16
Rp1 0.50 6513 -8.00857e-17 -3.20343e-16
Sox17 0.51 3957 -4.48729e-01 -4.23204e+00
... ... ... ... ...
AC149090.1 0.588462 1932 2.34565e-01 -4.59278e-02
DHRSX 0.530054 2050 -1.27333e-01 -4.52151e-01
Vmn2r122 0.500000 6513 -8.00857e-17 -3.20343e-16
CAAA01147332.1 0.505000 4893 7.27965e-01 -6.64274e-02
tomato-td 0.576875 1840 9.80090e-02 -2.20670e-01
median.logFC.detected max.logFC.detected rank.logFC.detected
<numeric> <numeric> <integer>
Xkr4 0.00000000 3.20343e-16 5560
Gm1992 0.00000000 3.20343e-16 5560
Gm37381 0.00000000 3.20343e-16 5560
Rp1 0.00000000 3.20343e-16 5560
Sox17 -0.00810194 1.51602e+00 341
... ... ... ...
AC149090.1 0.0821121 9.55592e-01 2039
DHRSX -0.1774204 2.28269e-01 3943
Vmn2r122 0.0000000 3.20343e-16 5560
CAAA01147332.1 0.8267364 1.00000e+00 898
tomato-td 0.0805999 4.63438e-01 3705Each column contains summary statistics for each gene in the given
cluster. These are usually the mean/median/min/max of statistics like
Cohen’s d and AUC when comparing this cluster (cluster 1 in
this case) to all other clusters. mean.AUC is usually the
most important to check. AUC is the probability that a randomly selected
cell in cluster A has a greater expression of gene X
than a randomly selected cell in cluster B. You can set
full.stats=TRUE if you’d like the marker data frames to
retain list columns containing each statistic for each pairwise
comparison.
We can then inspect the top marker genes for the first cluster using
the plotExpression function from the scater package.
R
c1_markers <- markers[[1]]
ord <- order(c1_markers$mean.AUC,
decreasing = TRUE)
top.markers <- head(rownames(c1_markers[ord,]))
plotExpression(sce,
features = top.markers,
x = "label",
color_by = "label")
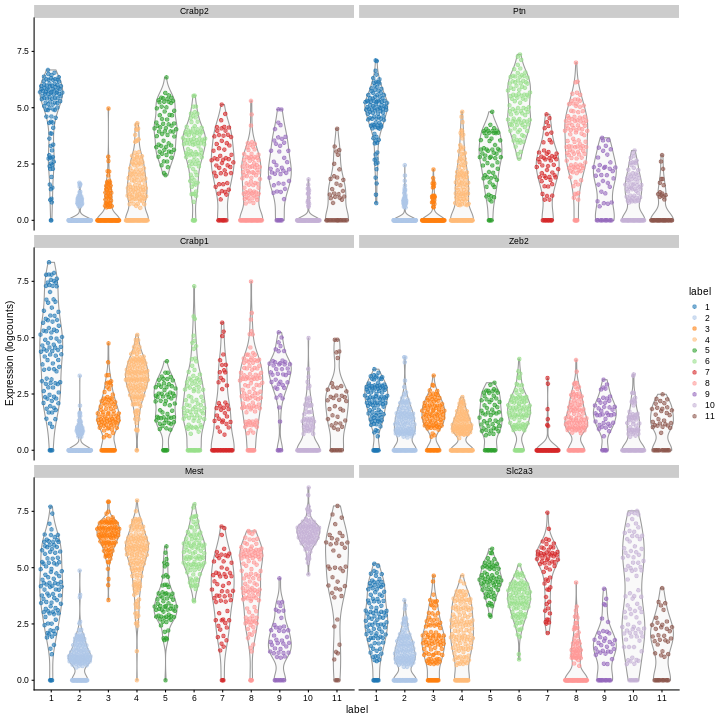
Clearly, not every marker gene distinguishes cluster 1 from every other cluster. However, with a combination of multiple marker genes it’s possible to clearly identify gene patterns that are unique to cluster 1. It’s sort of like the 20 questions game - with answers to the right questions about a cell (e.g. “Do you highly express Ptn?”), you can clearly identify what cluster it falls in.
Challenge
Looking at the last plot, what clusters are most difficult to distinguish from cluster 1? Now re-run the UMAP plot from the previous section. Do the difficult-to-distinguish clusters make sense?
You can see that at least among the top markers, cluster 6 (pale green) tends to have the least separation from cluster 1.
R
plotReducedDim(sce, "UMAP", color_by = "label")
Looking at the UMAP again, we can see that the marker gene overlap of clusters 1 and 6 makes sense. They’re right next to each other on the UMAP. They’re probably closely related cell types, and a less granular clustering would probably lump them together.
Cell type annotation
The most challenging task in scRNA-seq data analysis is arguably the interpretation of the results. Obtaining clusters of cells is fairly straightforward, but it is more difficult to determine what biological state is represented by each of those clusters. Doing so requires us to bridge the gap between the current dataset and prior biological knowledge, and the latter is not always available in a consistent and quantitative manner. Indeed, even the concept of a “cell type” is not clearly defined, with most practitioners possessing a “I’ll know it when I see it” intuition that is not amenable to computational analysis. As such, interpretation of scRNA-seq data is often manual and a common bottleneck in the analysis workflow.
To expedite this step, we can use various computational approaches that exploit prior information to assign meaning to an uncharacterized scRNA-seq dataset. The most obvious sources of prior information are the curated gene sets associated with particular biological processes, e.g., from the Gene Ontology (GO) or the Kyoto Encyclopedia of Genes and Genomes (KEGG) collections. Alternatively, we can directly compare our expression profiles to published reference datasets where each sample or cell has already been annotated with its putative biological state by domain experts. Here, we will demonstrate both approaches on the wild-type chimera dataset.
Assigning cell labels from reference data
A conceptually straightforward annotation approach is to compare the single-cell expression profiles with previously annotated reference datasets. Labels can then be assigned to each cell in our uncharacterized test dataset based on the most similar reference sample(s), for some definition of “similar”. This is a standard classification challenge that can be tackled by standard machine learning techniques such as random forests and support vector machines. Any published and labelled RNA-seq dataset (bulk or single-cell) can be used as a reference, though its reliability depends greatly on the expertise of the original authors who assigned the labels in the first place.
In this section, we will demonstrate the use of the SingleR method for cell type annotation Aran et al., 2019. This method assigns labels to cells based on the reference samples with the highest Spearman rank correlations, using only the marker genes between pairs of labels to focus on the relevant differences between cell types. It also performs a fine-tuning step for each cell where the correlations are recomputed with just the marker genes for the top-scoring labels. This aims to resolve any ambiguity between those labels by removing noise from irrelevant markers for other labels. Further details can be found in the SingleR book from which most of the examples here are derived.
Callout
Remember, the quality of reference-based cell type annotation can only be as good as the cell type assignments in the reference. Garbage in, garbage out. In practice, it’s worthwhile to spend time carefully assessing your to make sure the original assignments make sense and that it’s compatible with the query dataset you’re trying to annotate.
Here we take a single sample from EmbryoAtlasData as our
reference dataset. In practice you would want to take more/all samples,
possibly with batch-effect correction (see the next episode).
R
ref <- EmbryoAtlasData(samples = 29)
ref
OUTPUT
class: SingleCellExperiment
dim: 29452 7569
metadata(0):
assays(1): counts
rownames(29452): ENSMUSG00000051951 ENSMUSG00000089699 ...
ENSMUSG00000096730 ENSMUSG00000095742
rowData names(2): ENSEMBL SYMBOL
colnames(7569): cell_95727 cell_95728 ... cell_103294 cell_103295
colData names(17): cell barcode ... colour sizeFactor
reducedDimNames(2): pca.corrected umap
mainExpName: NULL
altExpNames(0):In order to reduce the computational load, we subsample the dataset to 1,000 cells.
R
set.seed(123)
ind <- sample(ncol(ref), 1000)
ref <- ref[,ind]
You can see we have an assortment of different cell types in the reference (with varying frequency):
R
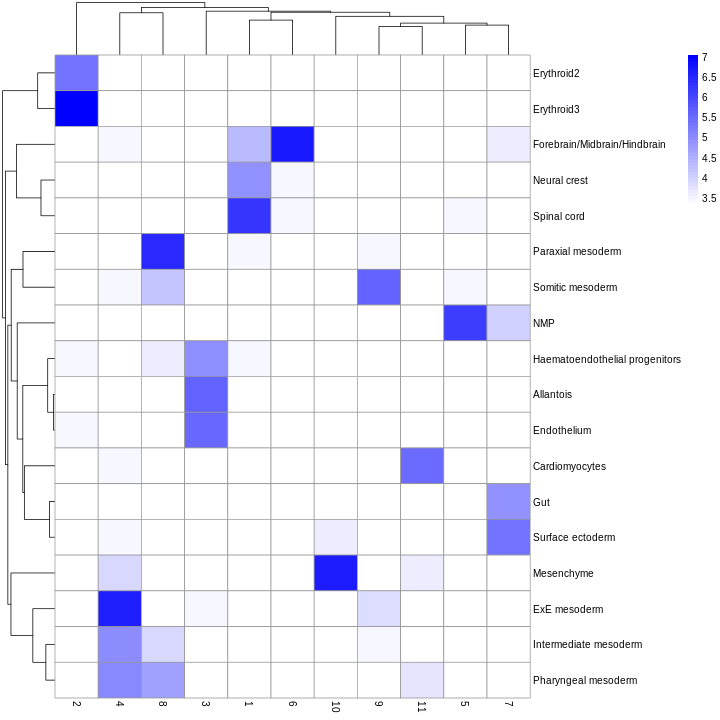
tab <- sort(table(ref$celltype), decreasing = TRUE)
tab
OUTPUT
Forebrain/Midbrain/Hindbrain Erythroid3
131 75
Paraxial mesoderm NMP
69 51
ExE mesoderm Surface ectoderm
49 47
Allantois Mesenchyme
46 45
Spinal cord Pharyngeal mesoderm
45 41
ExE endoderm Neural crest
38 35
Gut Haematoendothelial progenitors
30 27
Intermediate mesoderm Cardiomyocytes
27 26
Somitic mesoderm Endothelium
25 23
Erythroid2 Def. endoderm
11 3
Erythroid1 Blood progenitors 1
2 1
Blood progenitors 2 Caudal Mesoderm
1 1
PGC
1 We need the normalized log counts, so we add those on:
R
ref <- logNormCounts(ref)
Some cleaning - remove cells of the reference dataset for which the cell type annotation is missing:
R
nna <- !is.na(ref$celltype)
ref <- ref[,nna]
Also remove cell types of very low abundance (here less than 10 cells) to remove noise prior to subsequent annotation tasks.
R
abu.ct <- names(tab)[tab >= 10]
ind <- ref$celltype %in% abu.ct
ref <- ref[,ind]
Restrict to genes shared between query and reference dataset.
R
rownames(ref) <- rowData(ref)$SYMBOL
shared_genes <- intersect(rownames(sce), rownames(ref))
sce <- sce[shared_genes,]
ref <- ref[shared_genes,]
Convert sparse assay matrices to regular dense matrices for input to SingleR:
R
sce.mat <- as.matrix(assay(sce, "logcounts"))
ref.mat <- as.matrix(assay(ref, "logcounts"))
Finally, run SingleR with the query and reference datasets:
R
res <- SingleR(test = sce.mat,
ref = ref.mat,
labels = ref$celltype)
res
OUTPUT
DataFrame with 1000 rows and 4 columns
scores labels delta.next
<matrix> <character> <numeric>
cell_11995 0.348586:0.335451:0.314515:... Forebrain/Midbrain/H.. 0.1285110
cell_10294 0.273570:0.260013:0.298932:... Erythroid3 0.1381951
cell_9963 0.328538:0.291288:0.475611:... Endothelium 0.2193295
cell_11610 0.281161:0.269245:0.299961:... Erythroid3 0.0359215
cell_10910 0.422454:0.346897:0.355947:... ExE mesoderm 0.0984285
... ... ... ...
cell_11597 0.323805:0.292967:0.300485:... NMP 0.1663369
cell_9807 0.464466:0.374189:0.381698:... Mesenchyme 0.0833019
cell_10095 0.341721:0.288215:0.485324:... Endothelium 0.0889931
cell_11706 0.267487:0.240215:0.286012:... Erythroid2 0.0350557
cell_11860 0.345786:0.343437:0.313994:... Forebrain/Midbrain/H.. 0.0117001
pruned.labels
<character>
cell_11995 Forebrain/Midbrain/H..
cell_10294 Erythroid3
cell_9963 Endothelium
cell_11610 Erythroid3
cell_10910 ExE mesoderm
... ...
cell_11597 NMP
cell_9807 Mesenchyme
cell_10095 Endothelium
cell_11706 Erythroid2
cell_11860 Forebrain/Midbrain/H..We inspect the results using a heatmap of the per-cell and label scores. Ideally, each cell should exhibit a high score in one label relative to all of the others, indicating that the assignment to that label was unambiguous.
R
plotScoreHeatmap(res)
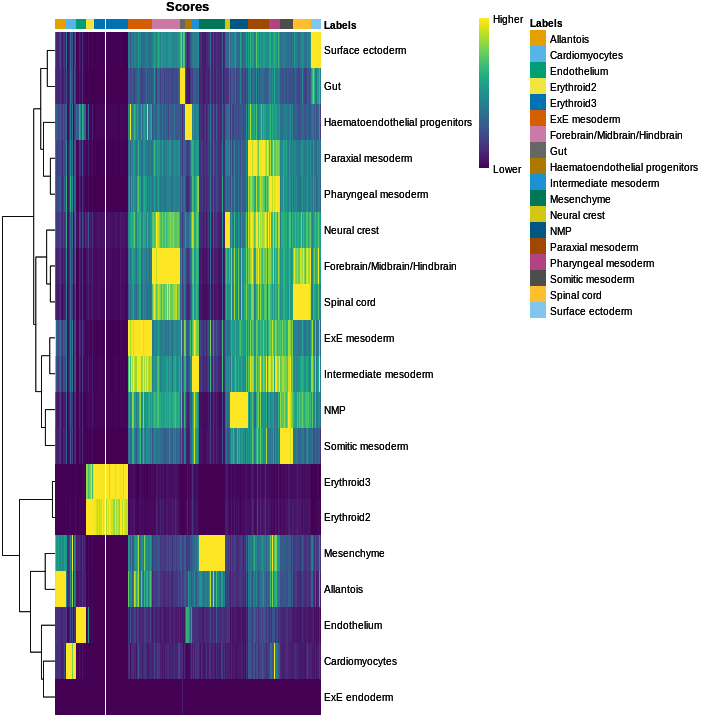
We obtained fairly unambiguous predictions for mesenchyme and endothelial cells, whereas we see expectedly more ambiguity between the two erythroid cell populations.
We can also compare the cell type assignments with the unsupervised clustering results to determine the identity of each cluster. Here, several cell type classes are nested within the same cluster, indicating that these clusters are composed of several transcriptomically similar cell populations. On the other hand, there are also instances where we have several clusters for the same cell type, indicating that the clustering represents finer subdivisions within these cell types.
R
tab <- table(anno = res$pruned.labels, cluster = colLabels(sce))
pheatmap(log2(tab + 10), color = colorRampPalette(c("white", "blue"))(101))
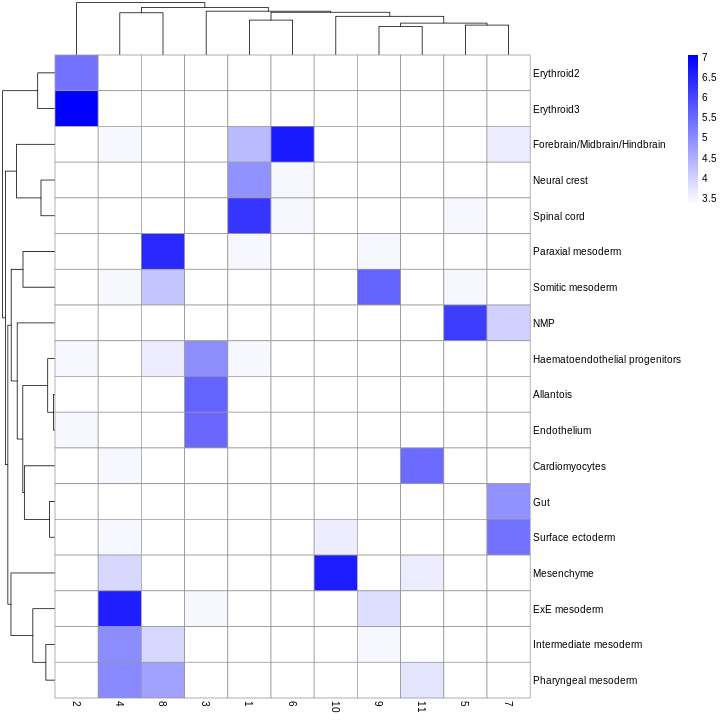
As it so happens, we are in the fortunate position where our test dataset also contains independently defined labels. We see strong consistency between the two sets of labels, indicating that our automatic annotation is comparable to that generated manually by domain experts.
R
tab <- table(res$pruned.labels, sce$celltype.mapped)
pheatmap(log2(tab + 10), color = colorRampPalette(c("white", "blue"))(101))
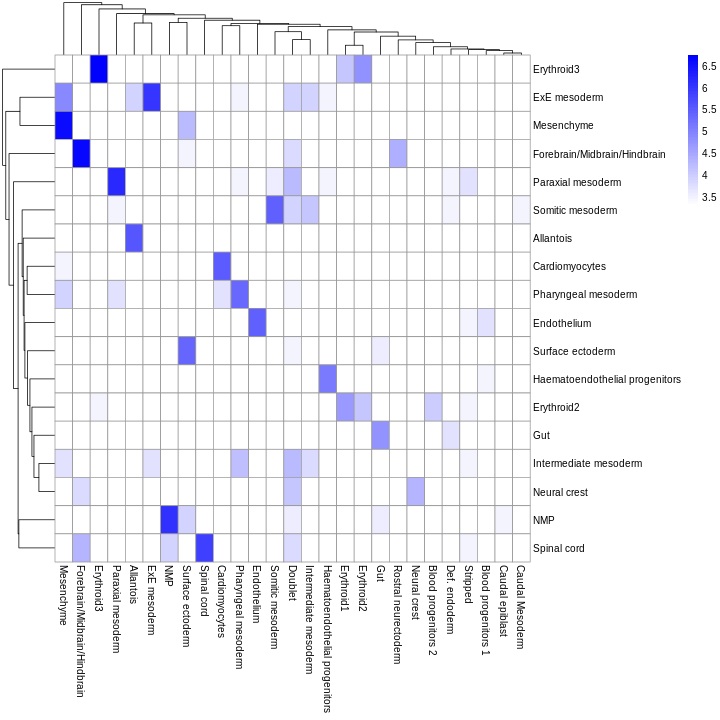
Challenge
Assign the SingleR annotations as a column in the colData for the
query object sce.
R
sce$SingleR_label = res$pruned.labels
Assigning cell labels from gene sets
A related strategy is to explicitly identify sets of marker genes that are highly expressed in each individual cell. This does not require matching of individual cells to the expression values of the reference dataset, which is faster and more convenient when only the identities of the markers are available. We demonstrate this approach using cell type markers derived from the mouse embryo atlas dataset.
R
wilcox.z <- pairwiseWilcox(ref, ref$celltype, lfc = 1, direction = "up")
markers.z <- getTopMarkers(wilcox.z$statistics, wilcox.z$pairs,
pairwise = FALSE, n = 50)
lengths(markers.z)
OUTPUT
Allantois Cardiomyocytes
106 106
Endothelium Erythroid2
103 54
Erythroid3 ExE endoderm
84 102
ExE mesoderm Forebrain/Midbrain/Hindbrain
97 97
Gut Haematoendothelial progenitors
90 71
Intermediate mesoderm Mesenchyme
70 118
Neural crest NMP
66 91
Paraxial mesoderm Pharyngeal mesoderm
88 85
Somitic mesoderm Spinal cord
86 91
Surface ectoderm
92 Our test dataset will be as before the wild-type chimera dataset.
R
sce
OUTPUT
class: SingleCellExperiment
dim: 29411 1000
metadata(0):
assays(2): counts logcounts
rownames(29411): Xkr4 Gm1992 ... Vmn2r122 CAAA01147332.1
rowData names(2): ENSEMBL SYMBOL
colnames(1000): cell_11995 cell_10294 ... cell_11706 cell_11860
colData names(14): cell barcode ... clust2 SingleR_label
reducedDimNames(4): pca.corrected.E7.5 pca.corrected.E8.5 PCA UMAP
mainExpName: NULL
altExpNames(0):We use the AUCell package to identify marker sets that are highly expressed in each cell. This method ranks genes by their expression values within each cell and constructs a response curve of the number of genes from each marker set that are present with increasing rank. It then computes the area under the curve (AUC) for each marker set, quantifying the enrichment of those markers among the most highly expressed genes in that cell. This is roughly similar to performing a Wilcoxon rank sum test between genes in and outside of the set, but involving only the top ranking genes by expression in each cell.
R
all.sets <- lapply(names(markers.z),
function(x) GeneSet(markers.z[[x]], setName = x))
all.sets <- GeneSetCollection(all.sets)
all.sets
OUTPUT
GeneSetCollection
names: Allantois, Cardiomyocytes, ..., Surface ectoderm (19 total)
unique identifiers: Phlda2, Spin2c, ..., Akr7a5 (991 total)
types in collection:
geneIdType: NullIdentifier (1 total)
collectionType: NullCollection (1 total)R
rankings <- AUCell_buildRankings(as.matrix(counts(sce)),
plotStats = FALSE, verbose = FALSE)
cell.aucs <- AUCell_calcAUC(all.sets, rankings)
results <- t(assay(cell.aucs))
head(results)
OUTPUT
gene sets
cells Allantois Cardiomyocytes Endothelium Erythroid2 Erythroid3
cell_11995 0.0691 0.0536 0.0459 0.1056 0.0948
cell_10294 0.0384 0.0370 0.0451 0.4910 0.5153
cell_9963 0.2177 0.1011 0.4380 0.1070 0.1087
cell_11610 0.0108 0.0428 0.0347 0.4687 0.4555
cell_10910 0.1868 0.0766 0.0869 0.0766 0.0682
cell_11021 0.0695 0.0596 0.0465 0.0991 0.0993
gene sets
cells ExE endoderm ExE mesoderm Forebrain/Midbrain/Hindbrain Gut
cell_11995 0.0342 0.1324 0.3173 0.1011
cell_10294 0.0680 0.0172 0.0439 0.0458
cell_9963 0.0686 0.1147 0.1116 0.1237
cell_11610 0.0573 0.0202 0.0460 0.0268
cell_10910 0.0764 0.3255 0.1747 0.1816
cell_11021 0.0680 0.2029 0.2500 0.1277
gene sets
cells Haematoendothelial progenitors Intermediate mesoderm Mesenchyme
cell_11995 0.0396 0.1627 0.0869
cell_10294 0.0371 0.0387 0.0369
cell_9963 0.3906 0.1157 0.2338
cell_11610 0.0258 0.0444 0.0324
cell_10910 0.1477 0.2265 0.2042
cell_11021 0.0473 0.2016 0.0814
gene sets
cells Neural crest NMP Paraxial mesoderm Pharyngeal mesoderm
cell_11995 0.208 0.1805 0.1889 0.1844
cell_10294 0.109 0.0445 0.0226 0.0263
cell_9963 0.145 0.1045 0.1706 0.1561
cell_11610 0.107 0.0640 0.0195 0.0294
cell_10910 0.135 0.2025 0.1437 0.1686
cell_11021 0.168 0.3432 0.1255 0.1515
gene sets
cells Somitic mesoderm Spinal cord Surface ectoderm
cell_11995 0.1279 0.2592 0.1611
cell_10294 0.0203 0.0633 0.0468
cell_9963 0.1197 0.1014 0.0850
cell_11610 0.0424 0.0692 0.0332
cell_10910 0.1787 0.1521 0.1043
cell_11021 0.2259 0.1974 0.1509We assign cell type identity to each cell in the test dataset by taking the marker set with the top AUC as the label for that cell. Our new labels mostly agree with the original annotation (and, thus, also with the reference-based annotation). Instances where the original annotation is divided into several new label groups typically points to large overlaps in their marker sets. In the absence of prior annotation, a more general diagnostic check is to compare the assigned labels to cluster identities, under the expectation that most cells of a single cluster would have the same label (or, if multiple labels are present, they should at least represent closely related cell states). We only print out the top-left corner of the table here, but you should try looking at the whole thing:
R
new.labels <- colnames(results)[max.col(results)]
tab <- table(new.labels, sce$celltype.mapped)
tab[1:4,1:4]
OUTPUT
new.labels Allantois Blood progenitors 1 Blood progenitors 2
Allantois 44 0 0
Cardiomyocytes 0 0 0
Endothelium 0 3 0
Erythroid2 0 1 7
new.labels Cardiomyocytes
Allantois 0
Cardiomyocytes 32
Endothelium 0
Erythroid2 0As a diagnostic measure, we examine the distribution of AUCs across cells for each label. In heterogeneous populations, the distribution for each label should be bimodal with one high-scoring peak containing cells of that cell type and a low-scoring peak containing cells of other types. The gap between these two peaks can be used to derive a threshold for whether a label is “active” for a particular cell. (In this case, we simply take the single highest-scoring label per cell as the labels should be mutually exclusive.) In populations where a particular cell type is expected, lack of clear bimodality for the corresponding label may indicate that its gene set is not sufficiently informative.
R
par(mfrow = c(3,3))
AUCell_exploreThresholds(cell.aucs[1:9], plotHist = TRUE, assign = TRUE)
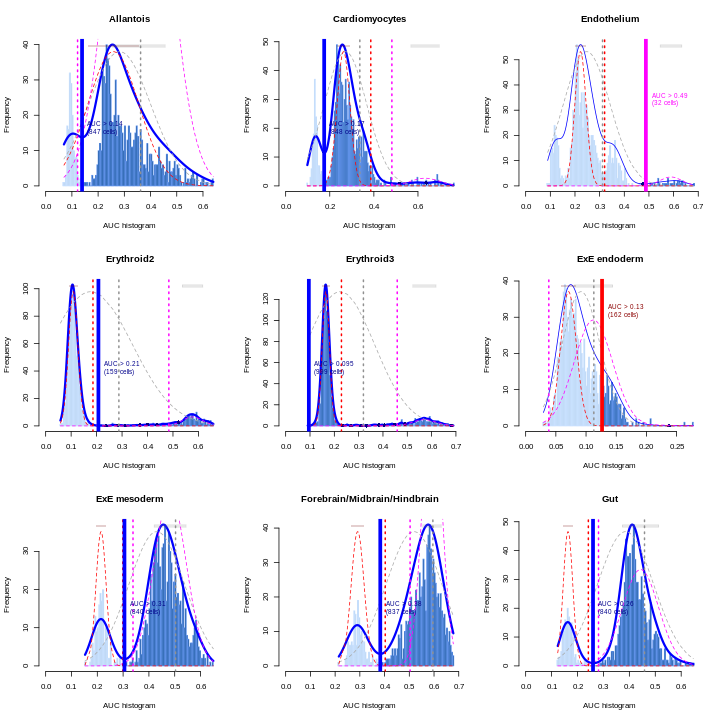
Shown is the distribution of AUCs in the wild-type chimera dataset for each label in the embryo atlas dataset. The blue curve represents the density estimate, the red curve represents a fitted two-component mixture of normals, the pink curve represents a fitted three-component mixture, and the grey curve represents a fitted normal distribution. Vertical lines represent threshold estimates corresponding to each estimate of the distribution.
Challenge
Inspect the diagnostics for the next nine cell types. Do they look okay?
R
par(mfrow = c(3,3))
AUCell_exploreThresholds(cell.aucs[10:18], plotHist = TRUE, assign = TRUE)
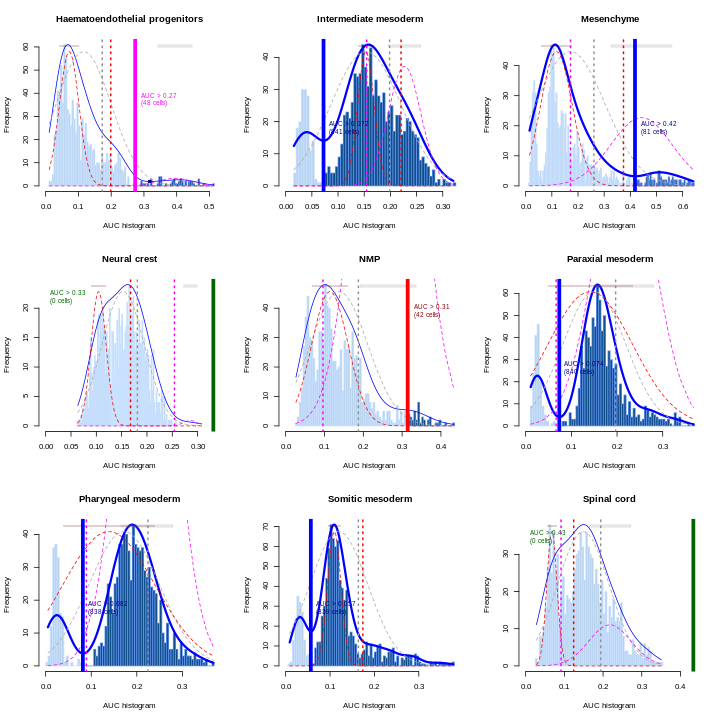
Exercises
Exercise 1: Clustering
The Leiden
algorithm is similar to the Louvain algorithm, but it is faster and
has been shown to result in better connected communities. Modify the
above call to clusterCells to carry out the community
detection with the Leiden algorithm instead. Visualize the results in a
UMAP plot.
The NNGraphParam constructor has an argument
cluster.args. This allows to specify arguments passed on to
the cluster_leiden function from the igraph
package. Use the cluster.args argument to parameterize the
clustering to use modularity as the objective function and a resolution
parameter of 0.5.
R
arg_list <- list(objective_function = "modularity",
resolution_parameter = .5)
sce$leiden_clust <- clusterCells(sce, use.dimred = "PCA",
BLUSPARAM = NNGraphParam(cluster.fun = "leiden",
cluster.args = arg_list))
plotReducedDim(sce, "UMAP", color_by = "leiden_clust")
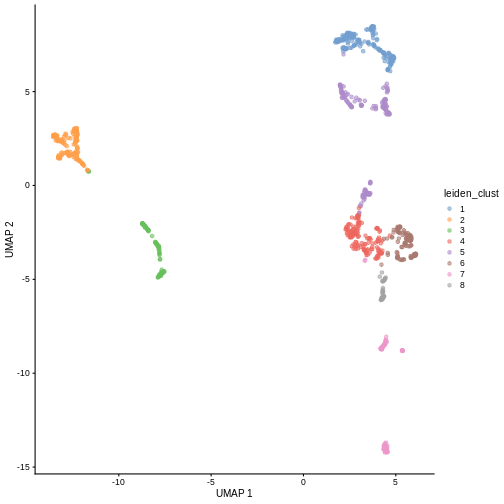
Exercise 2: Reference marker genes
Identify the marker genes in the reference single cell experiment,
using the celltype labels that come with the dataset as the
groups. Compare the top 100 marker genes of two cell types that are
close in UMAP space. Do they share similar marker sets?
R
markers <- scoreMarkers(ref, groups = ref$celltype)
markers
OUTPUT
List of length 19
names(19): Allantois Cardiomyocytes ... Spinal cord Surface ectodermR
# It comes with UMAP precomputed too
plotReducedDim(ref, dimred = "umap", color_by = "celltype")
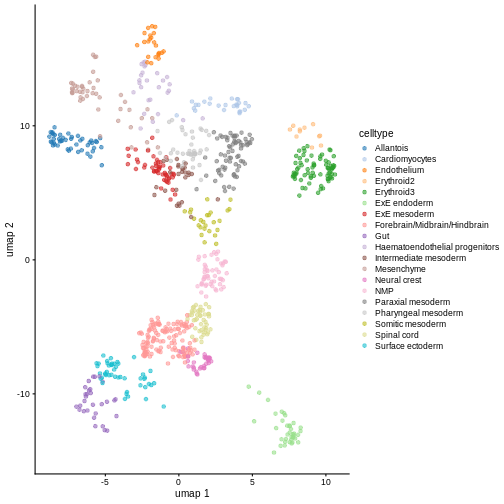
R
# Repetitive work -> write a function
order_marker_df <- function(m_df, n = 100) {
ord <- order(m_df$mean.AUC, decreasing = TRUE)
rownames(m_df[ord,][1:n,])
}
x <- order_marker_df(markers[["Erythroid2"]])
y <- order_marker_df(markers[["Erythroid3"]])
length(intersect(x,y)) / 100
OUTPUT
[1] 0.66Turns out there’s pretty substantial overlap between
Erythroid2 and Erythroid3. It would also be
interesting to plot the expression of the set difference to confirm that
the remainder are the the genes used to distinguish these two types from
each other.
Extension Challenge 1: Group pair comparisons
Why do you think marker genes are found by aggregating pairwise comparisons rather than iteratively comparing each cluster to all other clusters?
One important reason why is because averages over all other clusters can be sensitive to the cell type composition. If a rare cell type shows up in one sample, the most discriminative marker genes found in this way could be very different from those found in another sample where the rare cell type is absent.
Generally, it’s good to keep in mind that the concept of “everything else” is not a stable basis for comparison. Read that sentence again, because its a subtle but broadly applicable point. Think about it and you can probably identify analogous issues in fields outside of single-cell analysis. It frequently comes up when comparisons between multiple categories are involved.
Extension Challenge 2: Parallelizing SingleR
SingleR can be computationally expensive. How do you set it to run in parallel?
Use BiocParallel and the BPPARAM argument!
This example will set it to use four cores on your laptop, but you can
also configure BiocParallel to use cluster jobs.
R
library(BiocParallel)
my_bpparam <- MulticoreParam(workers = 4)
res2 <- SingleR(test = sce.mat,
ref = ref.mat,
labels = ref$celltype,
BPPARAM = my_bpparam)
BiocParallel is the most common way to enable parallel
computation in Bioconductor packages, so you can expect to see it
elsewhere outside of SingleR.
Extension Challenge 3: Critical inspection of diagnostics
The first set of AUCell diagnostics don’t look so good for some of the examples here. Which ones? Why?
The example that jumps out most strongly to the eye is ExE endoderm, which doesn’t show clear separate modes. Simultaneously, Endothelium seems to have three or four modes.
Remember, this is an exploratory diagnostic, not the final word! At this point it’d be good to engage in some critical inspection of the results. Maybe we don’t have enough / the best marker genes. In this particular case, the fact that we subsetted the reference set to 1000 cells probably didn’t help.
Further Reading
- OSCA book, Chapters 5-7
- Assigning cell types with SingleR (the book).
- The AUCell package vignette.
Key Points
- The two main approaches for cell type annotation are 1) manual annotation of clusters based on marker gene expression, and 2) computational annotation based on annotation transfer from reference datasets or marker gene set enrichment testing.
- For manual annotation, cells are first clustered with unsupervised methods such as graph-based clustering followed by community detection algorithms such as Louvain or Leiden.
- The
clusterCellsfunction from the scran package provides different algorithms that are commonly used for the clustering of scRNA-seq data. - Once clusters have been obtained, cell type labels are then manually assigned to cell clusters by matching cluster-specific upregulated marker genes with prior knowledge of cell-type markers.
- The
scoreMarkersfunction from the scran package package can be used to find candidate marker genes for clusters of cells by ranking differential expression between pairs of clusters. - Computational annotation using published reference datasets or curated gene sets provides a fast, automated, and reproducible alternative to the manual annotation of cell clusters based on marker gene expression.
- The SingleR package is a popular choice for reference-based annotation and assigns labels to cells based on the reference samples with the highest Spearman rank correlations.
- The AUCell package provides an enrichment test to identify curated marker sets that are highly expressed in each cell.
Session Info
R
sessionInfo()
OUTPUT
R version 4.4.1 (2024-06-14)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 22.04.5 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.10.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.10.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
time zone: UTC
tzcode source: system (glibc)
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] GSEABase_1.66.0 graph_1.82.0
[3] annotate_1.82.0 XML_3.99-0.16.1
[5] AnnotationDbi_1.66.0 pheatmap_1.0.12
[7] scran_1.32.0 scater_1.32.0
[9] ggplot2_3.5.1 scuttle_1.14.0
[11] bluster_1.14.0 SingleR_2.6.0
[13] MouseGastrulationData_1.18.0 SpatialExperiment_1.14.0
[15] SingleCellExperiment_1.26.0 SummarizedExperiment_1.34.0
[17] Biobase_2.64.0 GenomicRanges_1.56.0
[19] GenomeInfoDb_1.40.1 IRanges_2.38.0
[21] S4Vectors_0.42.0 BiocGenerics_0.50.0
[23] MatrixGenerics_1.16.0 matrixStats_1.3.0
[25] AUCell_1.26.0 BiocStyle_2.32.0
loaded via a namespace (and not attached):
[1] RColorBrewer_1.1-3 jsonlite_1.8.8
[3] magrittr_2.0.3 ggbeeswarm_0.7.2
[5] magick_2.8.3 farver_2.1.2
[7] rmarkdown_2.27 zlibbioc_1.50.0
[9] vctrs_0.6.5 memoise_2.0.1
[11] DelayedMatrixStats_1.26.0 htmltools_0.5.8.1
[13] S4Arrays_1.4.1 AnnotationHub_3.12.0
[15] curl_5.2.1 BiocNeighbors_1.22.0
[17] SparseArray_1.4.8 htmlwidgets_1.6.4
[19] plotly_4.10.4 cachem_1.1.0
[21] igraph_2.0.3 mime_0.12
[23] lifecycle_1.0.4 pkgconfig_2.0.3
[25] rsvd_1.0.5 Matrix_1.7-0
[27] R6_2.5.1 fastmap_1.2.0
[29] GenomeInfoDbData_1.2.12 digest_0.6.35
[31] colorspace_2.1-0 dqrng_0.4.1
[33] irlba_2.3.5.1 ExperimentHub_2.12.0
[35] RSQLite_2.3.7 beachmat_2.20.0
[37] labeling_0.4.3 filelock_1.0.3
[39] fansi_1.0.6 httr_1.4.7
[41] abind_1.4-5 compiler_4.4.1
[43] bit64_4.0.5 withr_3.0.0
[45] BiocParallel_1.38.0 viridis_0.6.5
[47] DBI_1.2.3 highr_0.11
[49] R.utils_2.12.3 MASS_7.3-60.2
[51] rappdirs_0.3.3 DelayedArray_0.30.1
[53] rjson_0.2.21 tools_4.4.1
[55] vipor_0.4.7 beeswarm_0.4.0
[57] R.oo_1.26.0 glue_1.7.0
[59] nlme_3.1-164 grid_4.4.1
[61] cluster_2.1.6 generics_0.1.3
[63] gtable_0.3.5 R.methodsS3_1.8.2
[65] tidyr_1.3.1 data.table_1.15.4
[67] BiocSingular_1.20.0 ScaledMatrix_1.12.0
[69] metapod_1.12.0 utf8_1.2.4
[71] XVector_0.44.0 ggrepel_0.9.5
[73] BiocVersion_3.19.1 pillar_1.9.0
[75] limma_3.60.2 BumpyMatrix_1.12.0
[77] splines_4.4.1 dplyr_1.1.4
[79] BiocFileCache_2.12.0 lattice_0.22-6
[81] survival_3.6-4 FNN_1.1.4
[83] renv_1.0.11 bit_4.0.5
[85] tidyselect_1.2.1 locfit_1.5-9.9
[87] Biostrings_2.72.1 knitr_1.47
[89] gridExtra_2.3 edgeR_4.2.0
[91] xfun_0.44 mixtools_2.0.0
[93] statmod_1.5.0 UCSC.utils_1.0.0
[95] lazyeval_0.2.2 yaml_2.3.8
[97] evaluate_0.23 codetools_0.2-20
[99] kernlab_0.9-32 tibble_3.2.1
[101] BiocManager_1.30.23 cli_3.6.2
[103] uwot_0.2.2 xtable_1.8-4
[105] segmented_2.1-0 munsell_0.5.1
[107] Rcpp_1.0.12 dbplyr_2.5.0
[109] png_0.1-8 parallel_4.4.1
[111] blob_1.2.4 sparseMatrixStats_1.16.0
[113] viridisLite_0.4.2 scales_1.3.0
[115] purrr_1.0.2 crayon_1.5.2
[117] rlang_1.1.3 formatR_1.14
[119] cowplot_1.1.3 KEGGREST_1.44.0 Content from Multi-sample analyses
Last updated on 2024-11-12 | Edit this page
Overview
Questions
- How can we integrate data from multiple batches, samples, and studies?
- How can we identify differentially expressed genes between experimental conditions for each cell type?
- How can we identify changes in cell type abundance between experimental conditions?
Objectives
- Correct batch effects and diagnose potential problems such as over-correction.
- Perform differential expression comparisons between conditions based on pseudo-bulk samples.
- Perform differential abundance comparisons between conditions.
Setup and data exploration
As before, we will use the the wild-type data from the Tal1 chimera experiment:
- Sample 5: E8.5 injected cells (tomato positive), pool 3
- Sample 6: E8.5 host cells (tomato negative), pool 3
- Sample 7: E8.5 injected cells (tomato positive), pool 4
- Sample 8: E8.5 host cells (tomato negative), pool 4
- Sample 9: E8.5 injected cells (tomato positive), pool 5
- Sample 10: E8.5 host cells (tomato negative), pool 5
Note that this is a paired design in which for each biological replicate (pool 3, 4, and 5), we have both host and injected cells.
We start by loading the data and doing a quick exploratory analysis,
essentially applying the normalization and visualization techniques that
we have seen in the previous lectures to all samples. Note that this
time we’re selecting samples 5 to 10, not just 5 by itself. Also note
the type = "processed" argument: we are explicitly
selecting the version of the data that has already been QC
processed.
R
library(MouseGastrulationData)
library(batchelor)
library(edgeR)
library(scater)
library(ggplot2)
library(scran)
library(pheatmap)
library(scuttle)
sce <- WTChimeraData(samples = 5:10, type = "processed")
sce
OUTPUT
class: SingleCellExperiment
dim: 29453 20935
metadata(0):
assays(1): counts
rownames(29453): ENSMUSG00000051951 ENSMUSG00000089699 ...
ENSMUSG00000095742 tomato-td
rowData names(2): ENSEMBL SYMBOL
colnames(20935): cell_9769 cell_9770 ... cell_30702 cell_30703
colData names(11): cell barcode ... doub.density sizeFactor
reducedDimNames(2): pca.corrected.E7.5 pca.corrected.E8.5
mainExpName: NULL
altExpNames(0):R
colData(sce)
OUTPUT
DataFrame with 20935 rows and 11 columns
cell barcode sample stage tomato
<character> <character> <integer> <character> <logical>
cell_9769 cell_9769 AAACCTGAGACTGTAA 5 E8.5 TRUE
cell_9770 cell_9770 AAACCTGAGATGCCTT 5 E8.5 TRUE
cell_9771 cell_9771 AAACCTGAGCAGCCTC 5 E8.5 TRUE
cell_9772 cell_9772 AAACCTGCATACTCTT 5 E8.5 TRUE
cell_9773 cell_9773 AAACGGGTCAACACCA 5 E8.5 TRUE
... ... ... ... ... ...
cell_30699 cell_30699 TTTGTCACAGCTCGCA 10 E8.5 FALSE
cell_30700 cell_30700 TTTGTCAGTCTAGTCA 10 E8.5 FALSE
cell_30701 cell_30701 TTTGTCATCATCGGAT 10 E8.5 FALSE
cell_30702 cell_30702 TTTGTCATCATTATCC 10 E8.5 FALSE
cell_30703 cell_30703 TTTGTCATCCCATTTA 10 E8.5 FALSE
pool stage.mapped celltype.mapped closest.cell
<integer> <character> <character> <character>
cell_9769 3 E8.25 Mesenchyme cell_24159
cell_9770 3 E8.5 Endothelium cell_96660
cell_9771 3 E8.5 Allantois cell_134982
cell_9772 3 E8.5 Erythroid3 cell_133892
cell_9773 3 E8.25 Erythroid1 cell_76296
... ... ... ... ...
cell_30699 5 E8.5 Erythroid3 cell_38810
cell_30700 5 E8.5 Surface ectoderm cell_38588
cell_30701 5 E8.25 Forebrain/Midbrain/H.. cell_66082
cell_30702 5 E8.5 Erythroid3 cell_138114
cell_30703 5 E8.0 Doublet cell_92644
doub.density sizeFactor
<numeric> <numeric>
cell_9769 0.02985045 1.41243
cell_9770 0.00172753 1.22757
cell_9771 0.01338013 1.15439
cell_9772 0.00218402 1.28676
cell_9773 0.00211723 1.78719
... ... ...
cell_30699 0.00146287 0.389311
cell_30700 0.00374155 0.588784
cell_30701 0.05651258 0.624455
cell_30702 0.00108837 0.550807
cell_30703 0.82369305 1.184919For the sake of making these examples run faster, we drop some problematic types (stripped nuclei and doublets) and also randomly select 50% cells per sample.
R
drop <- sce$celltype.mapped %in% c("stripped", "Doublet")
sce <- sce[,!drop]
set.seed(29482)
idx <- unlist(tapply(colnames(sce), sce$sample, function(x) {
perc <- round(0.50 * length(x))
sample(x, perc)
}))
sce <- sce[,idx]
We now normalize the data, run some dimensionality reduction steps,
and visualize them in a tSNE plot. In this case we happen to have a ton
of cell types to visualize, so we define a custom palette with a lot of
visually distinct colors (adapted from the polychrome
palette in the pals
package).
R
sce <- logNormCounts(sce)
dec <- modelGeneVar(sce, block = sce$sample)
chosen.hvgs <- dec$bio > 0
sce <- runPCA(sce, subset_row = chosen.hvgs, ntop = 1000)
sce <- runTSNE(sce, dimred = "PCA")
sce$sample <- as.factor(sce$sample)
plotTSNE(sce, colour_by = "sample")
R
color_vec <- c("#5A5156", "#E4E1E3", "#F6222E", "#FE00FA", "#16FF32", "#3283FE",
"#FEAF16", "#B00068", "#1CFFCE", "#90AD1C", "#2ED9FF", "#DEA0FD",
"#AA0DFE", "#F8A19F", "#325A9B", "#C4451C", "#1C8356", "#85660D",
"#B10DA1", "#3B00FB", "#1CBE4F", "#FA0087", "#333333", "#F7E1A0",
"#C075A6", "#782AB6", "#AAF400", "#BDCDFF", "#822E1C", "#B5EFB5",
"#7ED7D1", "#1C7F93", "#D85FF7", "#683B79", "#66B0FF", "#FBE426")
plotTSNE(sce, colour_by = "celltype.mapped") +
scale_color_manual(values = color_vec) +
theme(legend.position = "bottom")
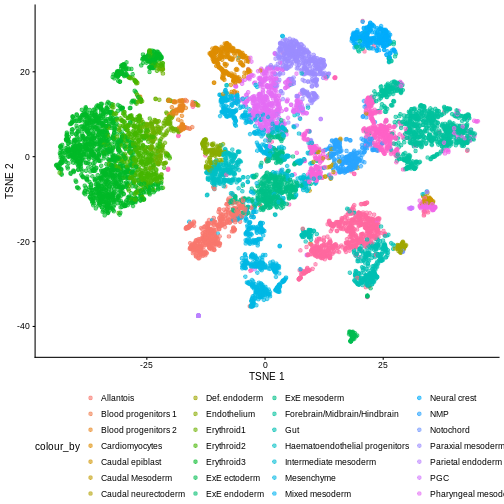
There are evident sample effects. Depending on the analysis that you want to perform you may want to remove or retain the sample effect. For instance, if the goal is to identify cell types with a clustering method, one may want to remove the sample effects with “batch effect” correction methods.
For now, let’s assume that we want to remove this effect.
Challenge
It seems like samples 5 and 6 are separated off from the others in gene expression space. Given the group of cells in each sample, why might this make sense versus some other pair of samples? What is the factor presumably leading to this difference?
Samples 5 and 6 were from the same “pool” of cells. Looking at the
documentation for the dataset under ?WTChimeraData we see
that the pool variable is defined as: “Integer, embryo pool from which
cell derived; samples with same value are matched.” So samples 5 and 6
have an experimental factor in common which causes a shared, systematic
difference in gene expression profiles compared to the other samples.
That’s why you can see many of isolated blue/orange clusters on the
first TSNE plot. If you were developing single-cell library preparation
protocols you might want to preserve this effect to understand how
variation in pools leads to variation in expression, but for now, given
that we’re investigating other effects, we’ll want to remove this as
undesired technical variation.
Correcting batch effects
We “correct” the effect of samples with the
correctExperiment function in the batchelor
package and using the sample column as batch.
R
set.seed(10102)
merged <- correctExperiments(
sce,
batch = sce$sample,
subset.row = chosen.hvgs,
PARAM = FastMnnParam(
merge.order = list(
list(1,3,5), # WT (3 replicates)
list(2,4,6) # td-Tomato (3 replicates)
)
)
)
merged <- runTSNE(merged, dimred = "corrected")
plotTSNE(merged, colour_by = "batch")
We can also see that when coloring by cell type, the cell types are now nicely confined to their own clusters for the most part:
R
plotTSNE(merged, colour_by = "celltype.mapped") +
scale_color_manual(values = color_vec) +
theme(legend.position = "bottom")
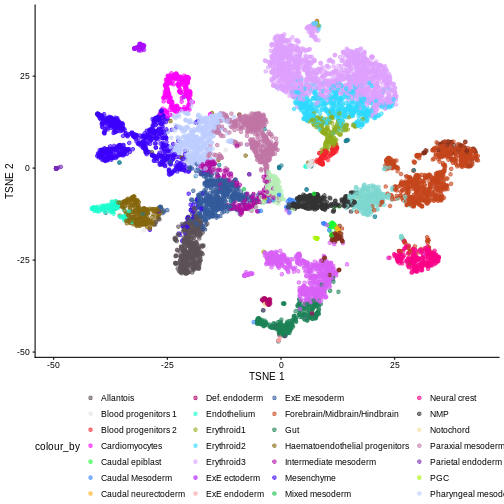
Once we removed the sample batch effect, we can proceed with the Differential Expression Analysis.
Challenge
True or False: after batch correction, no batch-level information is present in the corrected data.
False. Batch-level data can be retained through confounding with experimental factors or poor ability to distinguish experimental effects from batch effects. Remember, the changes needed to correct the data are empirically estimated, so they can carry along error.
While batch effect correction algorithms usually do a pretty good job, it’s smart to do a sanity check for batch effects at the end of your analysis. You always want to make sure that that effect you’re resting your paper submission on isn’t driven by batch effects.
Differential Expression
In order to perform a differential expression analysis, we need to identify groups of cells across samples/conditions (depending on the experimental design and the final aim of the experiment).
As previously seen, we have two ways of grouping cells, cell clustering and cell labeling. In our case we will focus on this second aspect to group cells according to the already annotated cell types to proceed with the computation of the pseudo-bulk samples.
Pseudo-bulk samples
To compute differences between groups of cells, a possible way is to compute pseudo-bulk samples, where we mediate the gene signal of all the cells for each specific cell type. In this manner, we are then able to detect differences between the same cell type across two different conditions.
To compute pseudo-bulk samples, we use the
aggregateAcrossCells function in the scuttle
package, which takes as input not only a SingleCellExperiment, but also
the id to use for the identification of the group of cells. In our case,
we use as id not just the cell type, but also the sample, because we
want be able to discern between replicates and conditions during further
steps.
R
# Using 'label' and 'sample' as our two factors; each column of the output
# corresponds to one unique combination of these two factors.
summed <- aggregateAcrossCells(
merged,
id = colData(merged)[,c("celltype.mapped", "sample")]
)
summed
OUTPUT
class: SingleCellExperiment
dim: 13641 179
metadata(2): merge.info pca.info
assays(1): counts
rownames(13641): ENSMUSG00000051951 ENSMUSG00000025900 ...
ENSMUSG00000096730 ENSMUSG00000095742
rowData names(3): rotation ENSEMBL SYMBOL
colnames: NULL
colData names(15): batch cell ... sample ncells
reducedDimNames(5): corrected pca.corrected.E7.5 pca.corrected.E8.5 PCA
TSNE
mainExpName: NULL
altExpNames(0):Differential Expression Analysis
The main advantage of using pseudo-bulk samples is the possibility to
use well-tested methods for differential analysis like
edgeR and DESeq2, we will focus on the former
for this analysis. edgeR and DESeq2 both use
negative binomial models under the hood, but differ in their
normalization strategies and other implementation details.
First, let’s start with a specific cell type, for instance the
“Mesenchymal stem cells”, and look into differences between this cell
type across conditions. We put the counts table into a
DGEList container called y, along with the
corresponding metadata.
R
current <- summed[, summed$celltype.mapped == "Mesenchyme"]
y <- DGEList(counts(current), samples = colData(current))
y
OUTPUT
An object of class "DGEList"
$counts
Sample1 Sample2 Sample3 Sample4 Sample5 Sample6
ENSMUSG00000051951 2 0 0 0 1 0
ENSMUSG00000025900 0 0 0 0 0 0
ENSMUSG00000025902 4 0 2 0 3 6
ENSMUSG00000033845 765 130 508 213 781 305
ENSMUSG00000002459 2 0 1 0 0 0
13636 more rows ...
$samples
group lib.size norm.factors batch cell barcode sample stage tomato pool
Sample1 1 2478901 1 5 <NA> <NA> 5 E8.5 TRUE 3
Sample2 1 548407 1 6 <NA> <NA> 6 E8.5 FALSE 3
Sample3 1 1260187 1 7 <NA> <NA> 7 E8.5 TRUE 4
Sample4 1 578699 1 8 <NA> <NA> 8 E8.5 FALSE 4
Sample5 1 2092329 1 9 <NA> <NA> 9 E8.5 TRUE 5
Sample6 1 904929 1 10 <NA> <NA> 10 E8.5 FALSE 5
stage.mapped celltype.mapped closest.cell doub.density sizeFactor
Sample1 <NA> Mesenchyme <NA> NA NA
Sample2 <NA> Mesenchyme <NA> NA NA
Sample3 <NA> Mesenchyme <NA> NA NA
Sample4 <NA> Mesenchyme <NA> NA NA
Sample5 <NA> Mesenchyme <NA> NA NA
Sample6 <NA> Mesenchyme <NA> NA NA
celltype.mapped.1 sample.1 ncells
Sample1 Mesenchyme 5 151
Sample2 Mesenchyme 6 28
Sample3 Mesenchyme 7 127
Sample4 Mesenchyme 8 75
Sample5 Mesenchyme 9 239
Sample6 Mesenchyme 10 146A typical step is to discard low quality samples due to low sequenced library size. We discard these samples because they can affect further steps like normalization and/or DEGs analysis.
We can see that in our case we don’t have low quality samples and we don’t need to filter out any of them.
R
discarded <- current$ncells < 10
y <- y[,!discarded]
summary(discarded)
OUTPUT
Mode FALSE
logical 6 The same idea is typically applied to the genes, indeed we need to discard low expressed genes to improve accuracy for the DEGs modeling.
R
keep <- filterByExpr(y, group = current$tomato)
y <- y[keep,]
summary(keep)
OUTPUT
Mode FALSE TRUE
logical 9121 4520 We can now proceed to normalize the data. There are several
approaches for normalizing bulk, and hence pseudo-bulk data. Here, we
use the Trimmed Mean of M-values method, implemented in the
edgeR package within the calcNormFactors
function. Keep in mind that because we are going to normalize the
pseudo-bulk counts, we don’t need to normalize the data in “single cell
form”.
R
y <- calcNormFactors(y)
y$samples
OUTPUT
group lib.size norm.factors batch cell barcode sample stage tomato pool
Sample1 1 2478901 1.0506857 5 <NA> <NA> 5 E8.5 TRUE 3
Sample2 1 548407 1.0399112 6 <NA> <NA> 6 E8.5 FALSE 3
Sample3 1 1260187 0.9700083 7 <NA> <NA> 7 E8.5 TRUE 4
Sample4 1 578699 0.9871129 8 <NA> <NA> 8 E8.5 FALSE 4
Sample5 1 2092329 0.9695559 9 <NA> <NA> 9 E8.5 TRUE 5
Sample6 1 904929 0.9858611 10 <NA> <NA> 10 E8.5 FALSE 5
stage.mapped celltype.mapped closest.cell doub.density sizeFactor
Sample1 <NA> Mesenchyme <NA> NA NA
Sample2 <NA> Mesenchyme <NA> NA NA
Sample3 <NA> Mesenchyme <NA> NA NA
Sample4 <NA> Mesenchyme <NA> NA NA
Sample5 <NA> Mesenchyme <NA> NA NA
Sample6 <NA> Mesenchyme <NA> NA NA
celltype.mapped.1 sample.1 ncells
Sample1 Mesenchyme 5 151
Sample2 Mesenchyme 6 28
Sample3 Mesenchyme 7 127
Sample4 Mesenchyme 8 75
Sample5 Mesenchyme 9 239
Sample6 Mesenchyme 10 146To investigate the effect of our normalization, we use a Mean-Difference (MD) plot for each sample in order to detect possible normalization problems due to insufficient cells/reads/UMIs composing a particular pseudo-bulk profile.
In our case, we verify that all these plots are centered in 0 (on y-axis) and present a trumpet shape, as expected.
R
par(mfrow = c(2,3))
for (i in seq_len(ncol(y))) {
plotMD(y, column = i)
}
R
par(mfrow = c(1,1))
Furthermore, we want to check if the samples cluster together based on their known factors (like the tomato injection in this case).
In this case, we’ll use the multidimensional scaling (MDS) plot. Multidimensional scaling (which also goes by principal coordinate analysis (PCoA)) is a dimensionality reduction technique that’s conceptually similar to principal component analysis (PCA).
R
limma::plotMDS(cpm(y, log = TRUE),
col = ifelse(y$samples$tomato, "red", "blue"))
We then construct a design matrix by including both the pool and the tomato as factors. This design indicates which samples belong to which pool and condition, so we can use it in the next step of the analysis.
R
design <- model.matrix(~factor(pool) + factor(tomato),
data = y$samples)
design
OUTPUT
(Intercept) factor(pool)4 factor(pool)5 factor(tomato)TRUE
Sample1 1 0 0 1
Sample2 1 0 0 0
Sample3 1 1 0 1
Sample4 1 1 0 0
Sample5 1 0 1 1
Sample6 1 0 1 0
attr(,"assign")
[1] 0 1 1 2
attr(,"contrasts")
attr(,"contrasts")$`factor(pool)`
[1] "contr.treatment"
attr(,"contrasts")$`factor(tomato)`
[1] "contr.treatment"Now we can estimate the Negative Binomial (NB) overdispersion parameter, to model the mean-variance trend.
R
y <- estimateDisp(y, design)
summary(y$trended.dispersion)
OUTPUT
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.009325 0.016271 0.024233 0.021603 0.026868 0.027993 The BCV plot allows us to investigate the relation between the
Biological Coefficient of Variation and the Average log CPM for each
gene. Additionally, the Common and Trend BCV are shown in
red and blue.
R
plotBCV(y)
We then fit a Quasi-Likelihood (QL) negative binomial generalized
linear model for each gene. The robust = TRUE parameter
avoids distortions from highly variable clusters. The QL method includes
an additional dispersion parameter, useful to handle the uncertainty and
variability of the per-gene variance, which is not well estimated by the
NB dispersions, so the two dispersion types complement each other in the
final analysis.
R
fit <- glmQLFit(y, design, robust = TRUE)
summary(fit$var.prior)
OUTPUT
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.3189 0.9705 1.0901 1.0251 1.1486 1.2151 R
summary(fit$df.prior)
OUTPUT
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.3046 8.7242 8.7242 8.6466 8.7242 8.7242 QL dispersion estimates for each gene as a function of abundance. Raw estimates (black) are shrunk towards the trend (blue) to yield squeezed estimates (red).
R
plotQLDisp(fit)
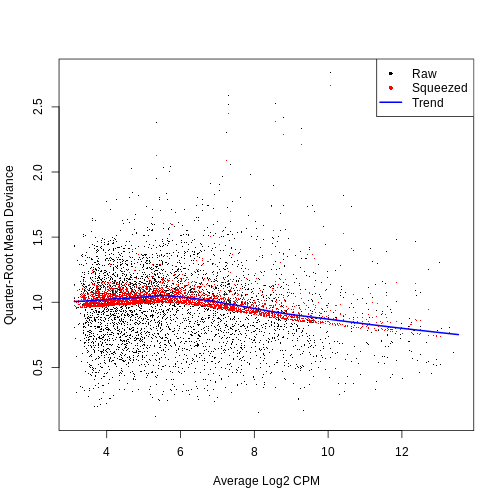
We then use an empirical Bayes quasi-likelihood F-test to test for differential expression (due to tomato injection) per each gene at a False Discovery Rate (FDR) of 5%. The low amount of DGEs highlights that the tomato injection effect has a low influence on the mesenchyme cells.
R
res <- glmQLFTest(fit, coef = ncol(design))
summary(decideTests(res))
OUTPUT
factor(tomato)TRUE
Down 5
NotSig 4510
Up 5R
topTags(res)
OUTPUT
Coefficient: factor(tomato)TRUE
logFC logCPM F PValue FDR
ENSMUSG00000010760 -4.1515323 9.973704 1118.17411 3.424939e-12 1.548073e-08
ENSMUSG00000096768 1.9987246 8.844258 375.41194 1.087431e-09 2.457594e-06
ENSMUSG00000035299 1.7963926 6.904163 119.08173 3.853318e-07 5.805666e-04
ENSMUSG00000086503 -6.4701526 7.411257 238.72531 1.114877e-06 1.259812e-03
ENSMUSG00000101609 1.3784805 7.310009 79.94279 2.682051e-06 2.424574e-03
ENSMUSG00000019188 -1.0191494 7.545530 62.01494 8.860823e-06 6.675153e-03
ENSMUSG00000024423 0.9940616 7.391075 56.84876 1.322645e-05 8.540506e-03
ENSMUSG00000042607 -0.9508732 7.468203 45.43086 3.625976e-05 2.048676e-02
ENSMUSG00000036446 -0.8280894 9.401028 43.03008 4.822988e-05 2.293136e-02
ENSMUSG00000027520 1.5929714 6.952923 42.86686 5.073310e-05 2.293136e-02All the previous steps can be easily performed with the following
function for each cell type, thanks to the pseudoBulkDGE
function in the scran package.
R
summed.filt <- summed[,summed$ncells >= 10]
de.results <- pseudoBulkDGE(
summed.filt,
label = summed.filt$celltype.mapped,
design = ~factor(pool) + tomato,
coef = "tomatoTRUE",
condition = summed.filt$tomato
)
The returned object is a list of DataFrames each with
the results for a cell type. Each of these contains also the
intermediate results in edgeR format to perform any
intermediate plot or diagnostic.
R
cur.results <- de.results[["Allantois"]]
cur.results[order(cur.results$PValue),]
OUTPUT
DataFrame with 13641 rows and 5 columns
logFC logCPM F PValue FDR
<numeric> <numeric> <numeric> <numeric> <numeric>
ENSMUSG00000037664 -7.993129 11.55290 2730.230 1.05747e-13 4.44242e-10
ENSMUSG00000010760 -2.575007 12.40592 1049.284 1.33098e-11 2.79572e-08
ENSMUSG00000086503 -7.015618 7.49749 788.150 5.88102e-11 8.23539e-08
ENSMUSG00000096768 1.828366 9.33239 343.044 3.58836e-09 3.76868e-06
ENSMUSG00000022464 0.970431 10.28302 126.467 4.59369e-07 3.85961e-04
... ... ... ... ... ...
ENSMUSG00000095247 NA NA NA NA NA
ENSMUSG00000096808 NA NA NA NA NA
ENSMUSG00000079808 NA NA NA NA NA
ENSMUSG00000096730 NA NA NA NA NA
ENSMUSG00000095742 NA NA NA NA NAChallenge
Clearly some of the results have low p-values. What about the effect
sizes? What does logFC stand for?
“logFC” stands for log fold-change. edgeR uses a log2
convention. Rather than reporting e.g. a 5-fold increase, it’s better to
report a logFC of log2(5) = 2.32. Additive log scales are easier to work
with than multiplicative identity scales, once you get used to it.
ENSMUSG00000037664 seems to have an estimated logFC of
about -8. That’s a big difference if it’s real.
Differential Abundance
With DA we look for differences in cluster abundance across conditions (the tomato injection in our case), rather than differences in gene expression.
Our first steps are quantifying the number of cells per each cell type and fitting a model to catch differences between the injected cells and the background.
The process is very similar differential expression modeling, but this time we start our analysis on the computed abundances and without normalizing the data with TMM.
R
abundances <- table(merged$celltype.mapped, merged$sample)
abundances <- unclass(abundances)
extra.info <- colData(merged)[match(colnames(abundances), merged$sample),]
y.ab <- DGEList(abundances, samples = extra.info)
design <- model.matrix(~factor(pool) + factor(tomato), y.ab$samples)
y.ab <- estimateDisp(y.ab, design, trend = "none")
fit.ab <- glmQLFit(y.ab, design, robust = TRUE, abundance.trend = FALSE)
Background on compositional effect
As mentioned before, in DA we don’t normalize our data with
calcNormFactors function, because this approach considers
that most of the input features do not vary between conditions. This
cannot be applied to DA analysis because we have a small number of cell
populations that all can change due to the treatment. This means that
here we will normalize only for library depth, which in pseudo-bulk data
means by the total number of cells in each sample (cell type).
On the other hand, this can lead our data to be susceptible to compositional effect. “Compositional” refers to the fact that the cluster abundances in a sample are not independent of one another because each cell type is effectively competing for space in the sample. They behave like proportions in that they must sum to 1. If cell type A abundance increases in a new condition, that means we’ll observe less of everything else, even if everything else is unaffected by the new condition.
Compositionality means that our conclusions can be biased by the amount of cells present in each cell type. And this amount of cells can be totally unbalanced between cell types. This is particularly problematic for cell types that start at or end up near 0 or 100 percent.
For example, a specific cell type can be 40% of the total amount of cells present in the experiment, while another just the 3%. The differences in terms of abundance of these cell types are detected between the different conditions, but our final interpretation could be biased if we don’t consider this aspect.
We now look at different approaches for handling the compositional effect.
Assuming most labels do not change
We can use a similar approach used during the DEGs analysis, assuming that most labels are not changing, in particular if we think about the low number of DEGs resulted from the previous analysis.
To do so, we first normalize the data with
calcNormFactors and then we fit and estimate a QL-model for
our abundance data.
R
y.ab2 <- calcNormFactors(y.ab)
y.ab2$samples$norm.factors
OUTPUT
[1] 1.1029040 1.0228173 1.0695358 0.7686501 1.0402941 1.0365354We then use edgeR in a manner similar to what we ran before:
R
y.ab2 <- estimateDisp(y.ab2, design, trend = "none")
fit.ab2 <- glmQLFit(y.ab2, design, robust = TRUE, abundance.trend = FALSE)
res2 <- glmQLFTest(fit.ab2, coef = ncol(design))
summary(decideTests(res2))
OUTPUT
factor(tomato)TRUE
Down 4
NotSig 29
Up 1R
topTags(res2, n = 10)
OUTPUT
Coefficient: factor(tomato)TRUE
logFC logCPM F PValue FDR
ExE ectoderm -5.7983253 13.13490 34.326044 1.497957e-07 5.093053e-06
Parietal endoderm -6.9219242 12.36649 21.805721 1.468320e-05 2.496144e-04
Erythroid3 -0.9115099 17.34677 12.478845 7.446554e-04 8.439428e-03
Mesenchyme 0.9796446 16.32654 11.692412 1.064808e-03 9.050865e-03
Neural crest -1.0469872 14.83912 7.956363 6.274678e-03 4.266781e-02
Endothelium 0.9241543 14.12195 4.437179 3.885736e-02 2.201917e-01
Erythroid2 -0.6029365 15.97357 3.737927 5.735479e-02 2.682206e-01
Cardiomyocytes 0.6789803 14.93321 3.569604 6.311073e-02 2.682206e-01
ExE endoderm -3.9996258 10.75172 3.086597 8.344133e-02 3.125815e-01
Allantois 0.5462287 15.54924 2.922074 9.193574e-02 3.125815e-01Testing against a log-fold change threshold
A second approach assumes that the composition bias introduces a spurious log2-fold change of no more than a quantity for a non-DA label.
In other words, we interpret this as the maximum log-fold change in the total number of cells given by DA in other labels. On the other hand, when choosing , we should not consider fold-differences in the totals due to differences in capture efficiency or the size of the original cell population are not attributable to composition bias. We then mitigate the effect of composition biases by testing each label for changes in abundance beyond .
R
res.lfc <- glmTreat(fit.ab, coef = ncol(design), lfc = 1)
summary(decideTests(res.lfc))
OUTPUT
factor(tomato)TRUE
Down 2
NotSig 32
Up 0R
topTags(res.lfc)
OUTPUT
Coefficient: factor(tomato)TRUE
logFC unshrunk.logFC logCPM PValue
ExE ectoderm -5.5156915 -5.9427658 13.06465 5.730409e-06
Parietal endoderm -6.5897795 -27.4235942 12.30091 1.215896e-04
ExE endoderm -3.9307381 -23.9369433 10.76159 7.352966e-02
Mesenchyme 1.1615857 1.1628182 16.35239 1.335104e-01
Endothelium 1.0564619 1.0620564 14.14422 2.136590e-01
Caudal neurectoderm -1.4588627 -1.6095620 11.09613 3.257325e-01
Cardiomyocytes 0.8521199 0.8545967 14.96579 3.649535e-01
Neural crest -0.8366836 -0.8392250 14.83184 3.750471e-01
Def. endoderm 0.7335519 0.7467590 12.50001 4.219471e-01
Allantois 0.7637525 0.7650565 15.54528 4.594987e-01
FDR
ExE ectoderm 0.0001948339
Parietal endoderm 0.0020670230
ExE endoderm 0.8333361231
Mesenchyme 0.9866105512
Endothelium 0.9866105512
Caudal neurectoderm 0.9866105512
Cardiomyocytes 0.9866105512
Neural crest 0.9866105512
Def. endoderm 0.9866105512
Allantois 0.9866105512Addionally, the choice of can be guided by other external experimental data, like a previous or a pilot experiment.
Exercises
Exercise 1: Heatmaps
Use the pheatmap package to create a heatmap of the
abundances table. Does it comport with the model results?
You can simply hand pheatmap() a matrix as its only
argument. pheatmap() has a million options you can adjust,
but the defaults are usually pretty good. Try to overlay sample-level
information with the annotation_col argument for an extra
challenge.
R
pheatmap(y.ab$counts)
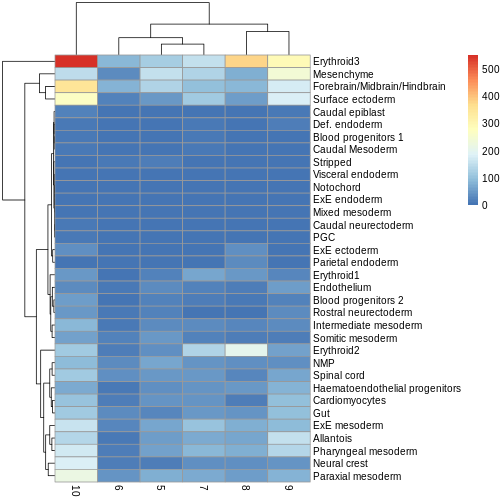
R
anno_df <- y.ab$samples[,c("tomato", "pool")]
anno_df$pool = as.character(anno_df$pool)
anno_df$tomato <- ifelse(anno_df$tomato,
"tomato+",
"tomato-")
pheatmap(y.ab$counts,
annotation_col = anno_df)
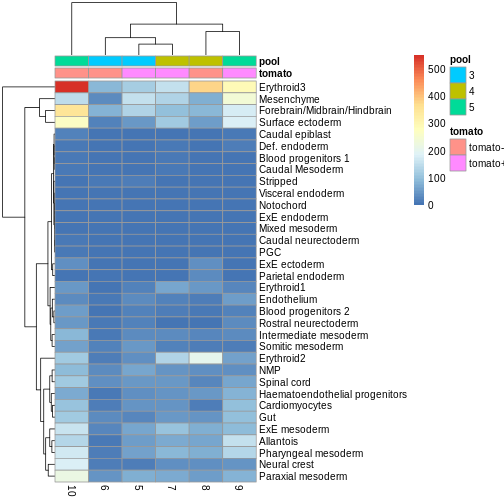
The top DA result was a decrease in ExE ectoderm in the tomato
condition, which you can sort of see, especially if you
log1p() the counts or discard rows that show much higher
values. ExE ectoderm counts were much higher in samples 8 and 10
compared to 5, 7, and 9.
Exercise 2: Model specification and comparison
Try re-running the pseudobulk DGE without the pool
factor in the design specification. Compare the logFC estimates and the
distribution of p-values for the Erythroid3 cell type.
After running the second pseudobulk DGE, you can join the two
DataFrames of Erythroid3 statistics using the
merge() function. You will need to create a common key
column from the gene IDs.
R
de.results2 <- pseudoBulkDGE(
summed.filt,
label = summed.filt$celltype.mapped,
design = ~tomato,
coef = "tomatoTRUE",
condition = summed.filt$tomato
)
eryth1 <- de.results$Erythroid3
eryth2 <- de.results2$Erythroid3
eryth1$gene <- rownames(eryth1)
eryth2$gene <- rownames(eryth2)
comp_df <- merge(eryth1, eryth2, by = 'gene')
comp_df <- comp_df[!is.na(comp_df$logFC.x),]
ggplot(comp_df, aes(logFC.x, logFC.y)) +
geom_abline(lty = 2, color = "grey") +
geom_point()
R
# Reshape to long format for ggplot facets. This is 1000x times easier to do
# with tidyverse packages:
pval_df <- reshape(comp_df[,c("gene", "PValue.x", "PValue.y")],
direction = "long",
v.names = "Pvalue",
timevar = "pool_factor",
times = c("with pool factor", "no pool factor"),
varying = c("PValue.x", "PValue.y"))
ggplot(pval_df, aes(Pvalue)) +
geom_histogram(boundary = 0,
bins = 30) +
facet_wrap("pool_factor")
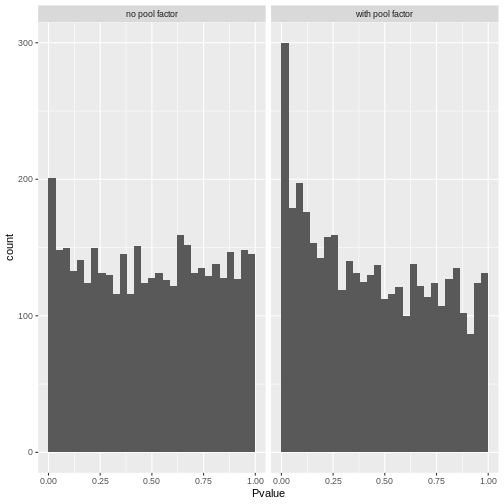
We can see that in this case, the logFC estimates are strongly
consistent between the two models, which tells us that the inclusion of
the pool factor in the model doesn’t strongly influence the
estimate of the tomato coefficients in this case.
The p-value histograms both look alright here, with a largely flat
plateau over most of the 0 - 1 range and a spike near 0. This is
consistent with the hypothesis that most genes are unaffected by
tomato but there are a small handful that clearly are.
If there were large shifts in the logFC estimates or p-value distributions, that’s a sign that the design specification change has a large impact on how the model sees the data. If that happens, you’ll need to think carefully and critically about what variables should and should not be included in the model formula.
Extension challenge 1: Group effects
Having multiple independent samples in each experimental group is always helpful, but it’s particularly important when it comes to batch effect correction. Why?
It’s important to have multiple samples within each experimental group because it helps the batch effect correction algorithm distinguish differences due to batch effects (uninteresting) from differences due to group/treatment/biology (interesting).
Imagine you had one sample that received a drug treatment and one that did not, each with 10,000 cells. They differ substantially in expression of gene X. Is that an important scientific finding? You can’t tell for sure, because the effect of drug is indistinguishable from a sample-wise batch effect. But if the difference in gene X holds up when you have five treated samples and five untreated samples, now you can be a bit more confident. Many batch effect correction methods will take information on experimental factors as additional arguments, which they can use to help remove batch effects while retaining experimental differences.
Further Reading
- OSCA book, Multi-sample analysis, Chapters 1, 4, and 6
Key Points
- Batch effects are systematic technical differences in the observed expression in cells measured in different experimental batches.
- Computational removal of batch-to-batch variation with the
correctExperimentfunction from the batchelor package allows us to combine data across multiple batches for a consolidated downstream analysis. - Differential expression (DE) analysis of replicated multi-condition scRNA-seq experiments is typically based on pseudo-bulk expression profiles, generated by summing counts for all cells with the same combination of label and sample.
- The
aggregateAcrossCellsfunction from the scater package facilitates the creation of pseudo-bulk samples.
- The
pseudoBulkDGEfunction from the scran package can be used to detect significant changes in expression between conditions for pseudo-bulk samples consisting of cells of the same type. - Differential abundance (DA) analysis aims at identifying significant changes in cell type abundance across conditions.
- DA analysis uses bulk DE methods such as edgeR and DESeq2, which provide suitable statistical models for count data in the presence of limited replication - except that the counts are not of reads per gene, but of cells per label.
Session Info
R
sessionInfo()
OUTPUT
R version 4.4.1 (2024-06-14)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 22.04.5 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.10.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.10.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
time zone: UTC
tzcode source: system (glibc)
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] pheatmap_1.0.12 scran_1.32.0
[3] scater_1.32.0 ggplot2_3.5.1
[5] scuttle_1.14.0 edgeR_4.2.0
[7] limma_3.60.2 batchelor_1.20.0
[9] MouseGastrulationData_1.18.0 SpatialExperiment_1.14.0
[11] SingleCellExperiment_1.26.0 SummarizedExperiment_1.34.0
[13] Biobase_2.64.0 GenomicRanges_1.56.0
[15] GenomeInfoDb_1.40.1 IRanges_2.38.0
[17] S4Vectors_0.42.0 BiocGenerics_0.50.0
[19] MatrixGenerics_1.16.0 matrixStats_1.3.0
[21] BiocStyle_2.32.0
loaded via a namespace (and not attached):
[1] RColorBrewer_1.1-3 jsonlite_1.8.8
[3] magrittr_2.0.3 ggbeeswarm_0.7.2
[5] magick_2.8.3 farver_2.1.2
[7] rmarkdown_2.27 zlibbioc_1.50.0
[9] vctrs_0.6.5 memoise_2.0.1
[11] DelayedMatrixStats_1.26.0 htmltools_0.5.8.1
[13] S4Arrays_1.4.1 AnnotationHub_3.12.0
[15] curl_5.2.1 BiocNeighbors_1.22.0
[17] SparseArray_1.4.8 cachem_1.1.0
[19] ResidualMatrix_1.14.0 igraph_2.0.3
[21] mime_0.12 lifecycle_1.0.4
[23] pkgconfig_2.0.3 rsvd_1.0.5
[25] Matrix_1.7-0 R6_2.5.1
[27] fastmap_1.2.0 GenomeInfoDbData_1.2.12
[29] digest_0.6.35 colorspace_2.1-0
[31] AnnotationDbi_1.66.0 dqrng_0.4.1
[33] irlba_2.3.5.1 ExperimentHub_2.12.0
[35] RSQLite_2.3.7 beachmat_2.20.0
[37] filelock_1.0.3 labeling_0.4.3
[39] fansi_1.0.6 httr_1.4.7
[41] abind_1.4-5 compiler_4.4.1
[43] bit64_4.0.5 withr_3.0.0
[45] BiocParallel_1.38.0 viridis_0.6.5
[47] DBI_1.2.3 highr_0.11
[49] rappdirs_0.3.3 DelayedArray_0.30.1
[51] rjson_0.2.21 bluster_1.14.0
[53] tools_4.4.1 vipor_0.4.7
[55] beeswarm_0.4.0 glue_1.7.0
[57] grid_4.4.1 Rtsne_0.17
[59] cluster_2.1.6 generics_0.1.3
[61] gtable_0.3.5 BiocSingular_1.20.0
[63] ScaledMatrix_1.12.0 metapod_1.12.0
[65] utf8_1.2.4 XVector_0.44.0
[67] ggrepel_0.9.5 BiocVersion_3.19.1
[69] pillar_1.9.0 BumpyMatrix_1.12.0
[71] splines_4.4.1 dplyr_1.1.4
[73] BiocFileCache_2.12.0 lattice_0.22-6
[75] renv_1.0.11 bit_4.0.5
[77] tidyselect_1.2.1 locfit_1.5-9.9
[79] Biostrings_2.72.1 knitr_1.47
[81] gridExtra_2.3 xfun_0.44
[83] statmod_1.5.0 UCSC.utils_1.0.0
[85] yaml_2.3.8 evaluate_0.23
[87] codetools_0.2-20 tibble_3.2.1
[89] BiocManager_1.30.23 cli_3.6.2
[91] munsell_0.5.1 Rcpp_1.0.12
[93] dbplyr_2.5.0 png_0.1-8
[95] parallel_4.4.1 blob_1.2.4
[97] sparseMatrixStats_1.16.0 viridisLite_0.4.2
[99] scales_1.3.0 purrr_1.0.2
[101] crayon_1.5.2 rlang_1.1.3
[103] cowplot_1.1.3 KEGGREST_1.44.0
[105] formatR_1.14 Content from Working with large data
Last updated on 2024-11-11 | Edit this page
Overview
Questions
- How do we work with single-cell datasets that are too large to fit in memory?
- How do we speed up single-cell analysis workflows for large datasets?
- How do we convert between popular single-cell data formats?
Objectives
- Work with out-of-memory data representations such as HDF5.
- Speed up single-cell analysis with parallel computation.
- Invoke fast approximations for essential analysis steps.
- Convert
SingleCellExperimentobjects toSeuratObjects andAnnDataobjects.
Motivation
Advances in scRNA-seq technologies have increased the number of cells that can be assayed in routine experiments. Public databases such as GEO are continually expanding with more scRNA-seq studies, while large-scale projects such as the Human Cell Atlas are expected to generate data for billions of cells. For effective data analysis, the computational methods need to scale with the increasing size of scRNA-seq data sets. This section discusses how we can use various aspects of the Bioconductor ecosystem to tune our analysis pipelines for greater speed and efficiency.
Out of memory representations
The count matrix is the central structure around which our analyses
are based. In most of the previous chapters, this has been held fully in
memory as a dense matrix or as a sparse
dgCMatrix. Howevever, in-memory representations may not be
feasible for very large data sets, especially on machines with limited
memory. For example, the 1.3 million brain cell data set from 10X
Genomics (Zheng et al.,
2017) would require over 100 GB of RAM to hold as a
matrix and around 30 GB as a dgCMatrix. This
makes it challenging to explore the data on anything less than a HPC
system.
The obvious solution is to use a file-backed matrix representation where the data are held on disk and subsets are retrieved into memory as requested. While a number of implementations of file-backed matrices are available (e.g., bigmemory, matter), we will be using the implementation from the HDF5Array package. This uses the popular HDF5 format as the underlying data store, which provides a measure of standardization and portability across systems. We demonstrate with a subset of 20,000 cells from the 1.3 million brain cell data set, as provided by the TENxBrainData package.
R
library(TENxBrainData)
sce.brain <- TENxBrainData20k()
sce.brain
OUTPUT
class: SingleCellExperiment
dim: 27998 20000
metadata(0):
assays(1): counts
rownames: NULL
rowData names(2): Ensembl Symbol
colnames: NULL
colData names(4): Barcode Sequence Library Mouse
reducedDimNames(0):
mainExpName: NULL
altExpNames(0):Examination of the SingleCellExperiment object indicates
that the count matrix is a HDF5Matrix. From a comparison of
the memory usage, it is clear that this matrix object is simply a stub
that points to the much larger HDF5 file that actually contains the
data. This avoids the need for large RAM availability during
analyses.
R
counts(sce.brain)
OUTPUT
<27998 x 20000> HDF5Matrix object of type "integer":
[,1] [,2] [,3] [,4] ... [,19997] [,19998] [,19999]
[1,] 0 0 0 0 . 0 0 0
[2,] 0 0 0 0 . 0 0 0
[3,] 0 0 0 0 . 0 0 0
[4,] 0 0 0 0 . 0 0 0
[5,] 0 0 0 0 . 0 0 0
... . . . . . . . .
[27994,] 0 0 0 0 . 0 0 0
[27995,] 0 0 0 1 . 0 2 0
[27996,] 0 0 0 0 . 0 1 0
[27997,] 0 0 0 0 . 0 0 0
[27998,] 0 0 0 0 . 0 0 0
[,20000]
[1,] 0
[2,] 0
[3,] 0
[4,] 0
[5,] 0
... .
[27994,] 0
[27995,] 0
[27996,] 0
[27997,] 0
[27998,] 0R
object.size(counts(sce.brain))
OUTPUT
2496 bytesR
file.info(path(counts(sce.brain)))$size
OUTPUT
[1] 76264332Manipulation of the count matrix will generally result in the
creation of a DelayedArray object from the DelayedArray
package. This remembers the operations to be applied to the counts and
stores them in the object, to be executed when the modified matrix
values are realized for use in calculations. The use of delayed
operations avoids the need to write the modified values to a new file at
every operation, which would unnecessarily require time-consuming disk
I/O.
R
tmp <- counts(sce.brain)
tmp <- log2(tmp + 1)
tmp
OUTPUT
<27998 x 20000> DelayedMatrix object of type "double":
[,1] [,2] [,3] ... [,19999] [,20000]
[1,] 0 0 0 . 0 0
[2,] 0 0 0 . 0 0
[3,] 0 0 0 . 0 0
[4,] 0 0 0 . 0 0
[5,] 0 0 0 . 0 0
... . . . . . .
[27994,] 0 0 0 . 0 0
[27995,] 0 0 0 . 0 0
[27996,] 0 0 0 . 0 0
[27997,] 0 0 0 . 0 0
[27998,] 0 0 0 . 0 0Many functions described in the previous workflows are capable of
accepting HDF5Matrix objects. This is powered by the
availability of common methods for all matrix representations (e.g.,
subsetting, combining, methods from DelayedMatrixStats
as well as representation-agnostic C++ code using beachmat. For
example, we compute QC metrics below with the same
calculateQCMetrics() function that we used in the other
workflows.
R
library(scater)
is.mito <- grepl("^mt-", rowData(sce.brain)$Symbol)
qcstats <- perCellQCMetrics(sce.brain, subsets = list(Mt = is.mito))
qcstats
OUTPUT
DataFrame with 20000 rows and 6 columns
sum detected subsets_Mt_sum subsets_Mt_detected subsets_Mt_percent
<numeric> <numeric> <numeric> <numeric> <numeric>
1 3060 1546 123 10 4.01961
2 3500 1694 118 11 3.37143
3 3092 1613 58 9 1.87581
4 4420 2050 131 10 2.96380
5 3771 1813 100 8 2.65182
... ... ... ... ... ...
19996 4431 2050 127 9 2.866170
19997 6988 2704 60 9 0.858615
19998 8749 2988 305 11 3.486113
19999 3842 1711 129 8 3.357626
20000 1775 945 26 6 1.464789
total
<numeric>
1 3060
2 3500
3 3092
4 4420
5 3771
... ...
19996 4431
19997 6988
19998 8749
19999 3842
20000 1775Needless to say, data access from file-backed representations is slower than that from in-memory representations. The time spent retrieving data from disk is an unavoidable cost of reducing memory usage. Whether this is tolerable depends on the application. One example usage pattern involves performing the heavy computing quickly with in-memory representations on HPC systems with plentiful memory, and then distributing file-backed counterparts to individual users for exploration and visualization on their personal machines.
Parallelization
Parallelization of calculations across genes or cells is an obvious strategy for speeding up scRNA-seq analysis workflows.
The BiocParallel
package provides a common interface for parallel computing throughout
the Bioconductor ecosystem, manifesting as a BPPARAM
argument in compatible functions. We can also use
BiocParallel with more expressive functions directly
through the package’s interface.
Basic use
R
library(BiocParallel)
BiocParallel makes it quite easy to iterate over a
vector and distribute the computation across workers using the
bplapply function. Basic knowledge of lapply
is required.
In this example, we find the square root of a vector of numbers in
parallel by indicating the BPPARAM argument in
bplapply.
R
param <- MulticoreParam(workers = 1)
bplapply(
X = c(4, 9, 16, 25),
FUN = sqrt,
BPPARAM = param
)
OUTPUT
[[1]]
[1] 2
[[2]]
[1] 3
[[3]]
[1] 4
[[4]]
[1] 5Note. The number of workers is set to 1 due to continuous testing resource limitations.
There exists a diverse set of parallelization backends depending on available hardware and operating systems.
For example, we might use forking across two cores to parallelize the variance calculations on a Unix system:
R
library(MouseGastrulationData)
library(scran)
sce <- WTChimeraData(samples = 5, type = "processed")
sce <- logNormCounts(sce)
dec.mc <- modelGeneVar(sce, BPPARAM = MulticoreParam(2))
dec.mc
OUTPUT
DataFrame with 29453 rows and 6 columns
mean total tech bio p.value
<numeric> <numeric> <numeric> <numeric> <numeric>
ENSMUSG00000051951 0.002800256 0.003504940 0.002856697 6.48243e-04 1.20905e-01
ENSMUSG00000089699 0.000000000 0.000000000 0.000000000 0.00000e+00 NaN
ENSMUSG00000102343 0.000000000 0.000000000 0.000000000 0.00000e+00 NaN
ENSMUSG00000025900 0.000794995 0.000863633 0.000811019 5.26143e-05 3.68953e-01
ENSMUSG00000025902 0.170777718 0.388633677 0.170891603 2.17742e-01 2.47893e-11
... ... ... ... ... ...
ENSMUSG00000095041 0.35571083 0.34572194 0.33640994 0.00931199 0.443233
ENSMUSG00000063897 0.49007956 0.41924282 0.44078158 -0.02153876 0.599499
ENSMUSG00000096730 0.00000000 0.00000000 0.00000000 0.00000000 NaN
ENSMUSG00000095742 0.00177158 0.00211619 0.00180729 0.00030890 0.188992
tomato-td 0.57257331 0.47487832 0.49719425 -0.02231593 0.591542
FDR
<numeric>
ENSMUSG00000051951 6.76255e-01
ENSMUSG00000089699 NaN
ENSMUSG00000102343 NaN
ENSMUSG00000025900 7.56202e-01
ENSMUSG00000025902 1.35508e-09
... ...
ENSMUSG00000095041 0.756202
ENSMUSG00000063897 0.756202
ENSMUSG00000096730 NaN
ENSMUSG00000095742 0.756202
tomato-td 0.756202Another approach would be to distribute jobs across a network of computers, which yields the same result:
R
dec.snow <- modelGeneVar(sce, BPPARAM = SnowParam(2))
For high-performance computing (HPC) systems with a cluster of
compute nodes, we can distribute jobs via the job scheduler using the
BatchtoolsParam class. The example below assumes a SLURM
cluster, though the settings can be easily configured for a particular
system (see here
for details).
R
# 2 hours, 8 GB, 1 CPU per task, for 10 tasks.
rs <- list(walltime = 7200, memory = 8000, ncpus = 1)
bpp <- BatchtoolsParam(10, cluster = "slurm", resources = rs)
Parallelization is best suited for independent, CPU-intensive tasks where the division of labor results in a concomitant reduction in compute time. It is not suited for tasks that are bounded by other compute resources, e.g., memory or file I/O (though the latter is less of an issue on HPC systems with parallel read/write). In particular, R itself is inherently single-core, so many of the parallelization backends involve (i) setting up one or more separate R sessions, (ii) loading the relevant packages and (iii) transmitting the data to that session. Depending on the nature and size of the task, this overhead may outweigh any benefit from parallel computing. While the default behavior of the parallel job managers often works well for simple cases, it is sometimes necessary to explicitly specify what data/libraries are sent to / loaded on the parallel workers in order to avoid unnecessary overhead.
Challenge
How do you turn on progress bars with parallel processing?
From ?MulticoreParam :
progressbarlogical(1) Enable progress bar (based on plyr:::progress_text). Enabling the progress bar changes the default value of tasks to .Machine$integer.max, so that progress is reported for each element of X.
Progress bars are a helpful way to gauge whether that task is going to take 5 minutes or 5 hours.
Fast approximations
Nearest neighbor searching
Identification of neighbouring cells in PC or expression space is a
common procedure that is used in many functions, e.g.,
buildSNNGraph(), doubletCells(). The default
is to favour accuracy over speed by using an exact nearest neighbour
(NN) search, implemented with the \(k\)-means for \(k\)-nearest neighbours algorithm. However,
for large data sets, it may be preferable to use a faster approximate
approach.
The BiocNeighbors
framework makes it easy to switch between search options by simply
changing the BNPARAM argument in compatible functions. To
demonstrate, we will use the wild-type chimera data for which we had
applied graph-based clustering using the Louvain algorithm for community
detection:
R
library(bluster)
sce <- runPCA(sce)
colLabels(sce) <- clusterCells(sce, use.dimred = "PCA",
BLUSPARAM = NNGraphParam(cluster.fun = "louvain"))
The above clusters on a nearest neighbor graph generated with an
exact neighbour search. We repeat this below using an approximate
search, implemented using the Annoy algorithm. This
involves constructing a AnnoyParam object to specify the
search algorithm and then passing it to the parameterization of the
NNGraphParam() function. The results from the exact and
approximate searches are consistent with most clusters from the former
re-appearing in the latter. This suggests that the inaccuracy from the
approximation can be largely ignored.
R
library(scran)
library(BiocNeighbors)
clusters <- clusterCells(sce, use.dimred = "PCA",
BLUSPARAM = NNGraphParam(cluster.fun = "louvain",
BNPARAM = AnnoyParam()))
table(exact = colLabels(sce), approx = clusters)
OUTPUT
approx
exact 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
1 91 0 0 0 0 0 0 0 0 0 0 1 0 0 0
2 0 143 0 0 0 0 0 0 0 0 0 0 0 0 1
3 0 0 75 0 0 0 0 0 0 0 0 0 0 0 0
4 0 0 0 341 0 0 0 0 0 0 0 0 0 0 56
5 0 0 2 0 74 0 0 0 0 0 0 320 0 0 0
6 0 0 0 0 0 81 246 0 0 0 2 0 0 0 0
7 0 0 0 0 0 128 0 0 0 0 0 0 0 0 0
8 0 0 0 0 95 0 0 0 0 0 0 0 0 0 0
9 0 0 0 0 0 0 0 108 0 0 0 1 0 0 0
10 0 0 0 0 0 0 0 0 113 0 0 0 0 0 0
11 0 0 0 0 0 2 0 0 7 139 0 0 6 0 0
12 0 0 0 0 7 0 0 0 0 0 205 1 0 0 0
13 0 0 0 0 0 0 2 0 0 0 0 0 143 0 1
14 0 0 0 0 0 0 0 0 0 0 0 0 0 20 0The similarity of the two clusterings can be quantified by calculating the pairwise Rand index:
R
rand <- pairwiseRand(colLabels(sce), clusters, mode = "index")
stopifnot(rand > 0.8)
Note that Annoy writes the NN index to disk prior to performing the search. Thus, it may not actually be faster than the default exact algorithm for small datasets, depending on whether the overhead of disk write is offset by the computational complexity of the search. It is also not difficult to find situations where the approximation deteriorates, especially at high dimensions, though this may not have an appreciable impact on the biological conclusions.
R
set.seed(1000)
y1 <- matrix(rnorm(50000), nrow = 1000)
y2 <- matrix(rnorm(50000), nrow = 1000)
Y <- rbind(y1, y2)
exact <- findKNN(Y, k = 20)
approx <- findKNN(Y, k = 20, BNPARAM = AnnoyParam())
mean(exact$index != approx$index)
OUTPUT
[1] 0.561925Singular value decomposition
The singular value decomposition (SVD) underlies the PCA used
throughout our analyses, e.g., in denoisePCA(),
fastMNN(), doubletCells(). (Briefly, the right
singular vectors are the eigenvectors of the gene-gene covariance
matrix, where each eigenvector represents the axis of maximum remaining
variation in the PCA.) The default base::svd() function
performs an exact SVD that is not performant for large datasets.
Instead, we use fast approximate methods from the irlba and
rsvd
packages, conveniently wrapped into the BiocSingular
package for ease of use and package development. Specifically, we can
change the SVD algorithm used in any of these functions by simply
specifying an alternative value for the BSPARAM
argument.
R
library(scater)
library(BiocSingular)
# As the name suggests, it is random, so we need to set the seed.
set.seed(101000)
r.out <- runPCA(sce, ncomponents = 20, BSPARAM = RandomParam())
str(reducedDim(r.out, "PCA"))
OUTPUT
num [1:2411, 1:20] 14.79 5.79 13.07 -32.19 -26.45 ...
- attr(*, "dimnames")=List of 2
..$ : chr [1:2411] "cell_9769" "cell_9770" "cell_9771" "cell_9772" ...
..$ : chr [1:20] "PC1" "PC2" "PC3" "PC4" ...
- attr(*, "varExplained")= num [1:20] 192.6 87 29.4 23.1 21.6 ...
- attr(*, "percentVar")= num [1:20] 25.84 11.67 3.94 3.1 2.89 ...
- attr(*, "rotation")= num [1:500, 1:20] -0.174 -0.173 -0.157 0.105 -0.132 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:500] "ENSMUSG00000055609" "ENSMUSG00000052217" "ENSMUSG00000069919" "ENSMUSG00000048583" ...
.. ..$ : chr [1:20] "PC1" "PC2" "PC3" "PC4" ...R
set.seed(101001)
i.out <- runPCA(sce, ncomponents = 20, BSPARAM = IrlbaParam())
str(reducedDim(i.out, "PCA"))
OUTPUT
num [1:2411, 1:20] -14.79 -5.79 -13.07 32.19 26.45 ...
- attr(*, "dimnames")=List of 2
..$ : chr [1:2411] "cell_9769" "cell_9770" "cell_9771" "cell_9772" ...
..$ : chr [1:20] "PC1" "PC2" "PC3" "PC4" ...
- attr(*, "varExplained")= num [1:20] 192.6 87 29.4 23.1 21.6 ...
- attr(*, "percentVar")= num [1:20] 25.84 11.67 3.94 3.1 2.89 ...
- attr(*, "rotation")= num [1:500, 1:20] 0.174 0.173 0.157 -0.105 0.132 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:500] "ENSMUSG00000055609" "ENSMUSG00000052217" "ENSMUSG00000069919" "ENSMUSG00000048583" ...
.. ..$ : chr [1:20] "PC1" "PC2" "PC3" "PC4" ...Both IRLBA and randomized SVD (RSVD) are much faster than the exact
SVD and usually yield only a negligible loss of accuracy. This motivates
their default use in many scran and
scater
functions, at the cost of requiring users to set the seed to guarantee
reproducibility. IRLBA can occasionally fail to converge and require
more iterations (passed via maxit= in
IrlbaParam()), while RSVD involves an explicit trade-off
between accuracy and speed based on its oversampling parameter
(p=) and number of power iterations (q=). We
tend to prefer IRLBA as its default behavior is more accurate, though
RSVD is much faster for file-backed matrices.
Challenge
The uncertainty from approximation error is sometimes aggravating.
“Why can’t my computer just give me the right answer?” One way to
alleviate this feeling is to quantify the approximation error on a small
test set like the sce we have here. Using the ExactParam()
class, visualize the error in PC1 coordinates compared to the RSVD
results.
This code block calculates the exact PCA coordinates. Another thing to note: PC vectors are only identified up to a sign flip. We can see that the RSVD PC1 vector points in the
R
set.seed(123)
e.out <- runPCA(sce, ncomponents = 20, BSPARAM = ExactParam())
str(reducedDim(e.out, "PCA"))
OUTPUT
num [1:2411, 1:20] -14.79 -5.79 -13.07 32.19 26.45 ...
- attr(*, "dimnames")=List of 2
..$ : chr [1:2411] "cell_9769" "cell_9770" "cell_9771" "cell_9772" ...
..$ : chr [1:20] "PC1" "PC2" "PC3" "PC4" ...
- attr(*, "varExplained")= num [1:20] 192.6 87 29.4 23.1 21.6 ...
- attr(*, "percentVar")= num [1:20] 25.84 11.67 3.94 3.1 2.89 ...
- attr(*, "rotation")= num [1:500, 1:20] 0.174 0.173 0.157 -0.105 0.132 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:500] "ENSMUSG00000055609" "ENSMUSG00000052217" "ENSMUSG00000069919" "ENSMUSG00000048583" ...
.. ..$ : chr [1:20] "PC1" "PC2" "PC3" "PC4" ...R
reducedDim(e.out, "PCA")[1:5,1:3]
OUTPUT
PC1 PC2 PC3
cell_9769 -14.793684 18.470324 -0.4893474
cell_9770 -5.789032 13.347277 5.0560761
cell_9771 -13.066503 16.803152 -0.5602737
cell_9772 32.185950 6.697517 -0.6945423
cell_9773 26.452390 3.083474 -0.2271916R
reducedDim(r.out, "PCA")[1:5,1:3]
OUTPUT
PC1 PC2 PC3
cell_9769 14.793780 18.470111 -0.4888676
cell_9770 5.789148 13.348438 5.0702153
cell_9771 13.066327 16.803423 -0.5562241
cell_9772 -32.186341 6.698347 -0.6892421
cell_9773 -26.452373 3.083974 -0.2299814For the sake of visualizing the error we can just flip the PC1 coordinates:
R
reducedDim(r.out, "PCA") = -1 * reducedDim(r.out, "PCA")
From there we can visualize the error with a histogram:
R
error <- reducedDim(r.out, "PCA")[,"PC1"] -
reducedDim(e.out, "PCA")[,"PC1"]
data.frame(approx_error = error) |>
ggplot(aes(approx_error)) +
geom_histogram()
It’s almost never more than .001 in this case.
Interoperability with popular single-cell analysis ecosytems
Seurat
Seurat is an R package designed for QC, analysis, and exploration of single-cell RNA-seq data. Seurat can be used to identify and interpret sources of heterogeneity from single-cell transcriptomic measurements, and to integrate diverse types of single-cell data. Seurat is developed and maintained by the Satija lab and is released under the MIT license.
R
library(Seurat)
Although the basic processing of single-cell data with Bioconductor
packages (described in the OSCA book) and
with Seurat is very similar and will produce overall roughly identical
results, there is also complementary functionality with regard to cell
type annotation, dataset integration, and downstream analysis. To make
the most of both ecosystems it is therefore beneficial to be able to
easily switch between a SeuratObject and a
SingleCellExperiment. See also the Seurat conversion
vignette for conversion to/from other popular single cell formats
such as the AnnData format used by scanpy.
Here, we demonstrate converting the Seurat object produced in
Seurat’s PBMC
tutorial to a SingleCellExperiment for further analysis
with functionality from OSCA/Bioconductor. We therefore need to first
install the SeuratData package,
which is available from GitHub only.
R
BiocManager::install("satijalab/seurat-data")
We then proceed by loading all required packages and installing the PBMC dataset:
R
library(SeuratData)
InstallData("pbmc3k")
We then load the dataset as an SeuratObject and convert
it to a SingleCellExperiment.
R
# Use PBMC3K from SeuratData
pbmc <- LoadData(ds = "pbmc3k", type = "pbmc3k.final")
pbmc <- UpdateSeuratObject(pbmc)
pbmc
pbmc.sce <- as.SingleCellExperiment(pbmc)
pbmc.sce
Seurat also allows conversion from SingleCellExperiment
objects to Seurat objects; we demonstrate this here on the wild-type
chimera mouse gastrulation dataset.
R
sce <- WTChimeraData(samples = 5, type = "processed")
assay(sce) <- as.matrix(assay(sce))
sce <- logNormCounts(sce)
sce
After some processing of the dataset, the actual conversion is
carried out with the as.Seurat function.
R
sobj <- as.Seurat(sce)
Idents(sobj) <- "celltype.mapped"
sobj
Scanpy
Scanpy is a scalable toolkit for analyzing single-cell gene expression data built jointly with anndata. It includes preprocessing, visualization, clustering, trajectory inference and differential expression testing. The Python-based implementation efficiently deals with datasets of more than one million cells. Scanpy is developed and maintained by the Theis lab and is released under a BSD-3-Clause license. Scanpy is part of the scverse, a Python-based ecosystem for single-cell omics data analysis.
At the core of scanpy’s single-cell functionality is the
anndata data structure, scanpy’s integrated single-cell
data container, which is conceptually very similar to Bioconductor’s
SingleCellExperiment class.
Bioconductor’s zellkonverter
package provides a lightweight interface between the Bioconductor
SingleCellExperiment data structure and the Python
AnnData-based single-cell analysis environment. The idea is
to enable users and developers to easily move data between these
frameworks to construct a multi-language analysis pipeline across
R/Bioconductor and Python.
R
library(zellkonverter)
The readH5AD() function can be used to read a
SingleCellExperiment from an H5AD file. Here, we use an
example H5AD file contained in the zellkonverter
package.
R
example_h5ad <- system.file("extdata", "krumsiek11.h5ad",
package = "zellkonverter")
readH5AD(example_h5ad)
OUTPUT
class: SingleCellExperiment
dim: 11 640
metadata(2): highlights iroot
assays(1): X
rownames(11): Gata2 Gata1 ... EgrNab Gfi1
rowData names(0):
colnames(640): 0 1 ... 158-3 159-3
colData names(1): cell_type
reducedDimNames(0):
mainExpName: NULL
altExpNames(0):We can also write a SingleCellExperiment to an H5AD file
with the writeH5AD() function. This is demonstrated below
on the wild-type chimera mouse gastrulation dataset.
R
out.file <- tempfile(fileext = ".h5ad")
writeH5AD(sce, file = out.file)
The resulting H5AD file can then be read into Python using scanpy’s read_h5ad function and then directly used in compatible Python-based analysis frameworks.
Exercises
Exercise 1: Out of memory representation
Write the counts matrix of the wild-type chimera mouse gastrulation dataset to an HDF5 file. Create another counts matrix that reads the data from the HDF5 file. Compare memory usage of holding the entire matrix in memory as opposed to holding the data out of memory.
See the HDF5Array function for reading from HDF5 and the
writeHDF5Array function for writing to HDF5 from the HDF5Array
package.
R
wt_out <- tempfile(fileext = ".h5")
wt_counts <- counts(WTChimeraData())
writeHDF5Array(wt_counts,
name = "wt_counts",
file = wt_out)
OUTPUT
<29453 x 30703> sparse HDF5Matrix object of type "double":
cell_1 cell_2 cell_3 ... cell_30702 cell_30703
ENSMUSG00000051951 0 0 0 . 0 0
ENSMUSG00000089699 0 0 0 . 0 0
ENSMUSG00000102343 0 0 0 . 0 0
ENSMUSG00000025900 0 0 0 . 0 0
ENSMUSG00000025902 0 0 0 . 0 0
... . . . . . .
ENSMUSG00000095041 0 1 2 . 0 0
ENSMUSG00000063897 0 0 0 . 0 0
ENSMUSG00000096730 0 0 0 . 0 0
ENSMUSG00000095742 0 0 0 . 0 0
tomato-td 1 0 1 . 0 0R
oom_wt <- HDF5Array(wt_out, "wt_counts")
object.size(wt_counts)
OUTPUT
1520366960 bytesR
object.size(oom_wt)
OUTPUT
2488 bytesExercise 2: Parallelization
Perform a PCA analysis of the wild-type chimera mouse gastrulation dataset using a multicore backend for parallel computation. Compare the runtime of performing the PCA either in serial execution mode, in multicore execution mode with 2 workers, and in multicore execution mode with 3 workers.
Use the function system.time to obtain the runtime of
each job.
R
sce.brain <- logNormCounts(sce.brain)
system.time({i.out <- runPCA(sce.brain,
ncomponents = 20,
BSPARAM = ExactParam(),
BPPARAM = SerialParam())})
system.time({i.out <- runPCA(sce.brain,
ncomponents = 20,
BSPARAM = ExactParam(),
BPPARAM = MulticoreParam(workers = 2))})
system.time({i.out <- runPCA(sce.brain,
ncomponents = 20,
BSPARAM = ExactParam(),
BPPARAM = MulticoreParam(workers = 3))})
Further Reading
- OSCA book, Chapter 14: Dealing with big data
- The
BiocParallelintro vignette.
Key Points
- Out-of-memory representations can be used to work with single-cell datasets that are too large to fit in memory.
- Parallelization of calculations across genes or cells is an effective strategy for speeding up analysis of large single-cell datasets.
- Fast approximations for nearest neighbor search and singular value composition can speed up essential steps of single-cell analysis with minimal loss of accuracy.
- Converter functions between existing single-cell data formats enable analysis workflows that leverage complementary functionality from poplular single-cell analysis ecosystems.
Session Info
R
sessionInfo()
OUTPUT
R version 4.4.1 (2024-06-14)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 22.04.5 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.10.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.10.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
time zone: UTC
tzcode source: system (glibc)
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] zellkonverter_1.14.0 Seurat_5.1.0
[3] SeuratObject_5.0.2 sp_2.1-4
[5] BiocSingular_1.20.0 BiocNeighbors_1.22.0
[7] bluster_1.14.0 scran_1.32.0
[9] MouseGastrulationData_1.18.0 SpatialExperiment_1.14.0
[11] BiocParallel_1.38.0 scater_1.32.0
[13] ggplot2_3.5.1 scuttle_1.14.0
[15] TENxBrainData_1.24.0 HDF5Array_1.32.0
[17] rhdf5_2.48.0 DelayedArray_0.30.1
[19] SparseArray_1.4.8 S4Arrays_1.4.1
[21] abind_1.4-5 Matrix_1.7-0
[23] SingleCellExperiment_1.26.0 SummarizedExperiment_1.34.0
[25] Biobase_2.64.0 GenomicRanges_1.56.0
[27] GenomeInfoDb_1.40.1 IRanges_2.38.0
[29] S4Vectors_0.42.0 BiocGenerics_0.50.0
[31] MatrixGenerics_1.16.0 matrixStats_1.3.0
[33] BiocStyle_2.32.0
loaded via a namespace (and not attached):
[1] spatstat.sparse_3.0-3 httr_1.4.7
[3] RColorBrewer_1.1-3 tools_4.4.1
[5] sctransform_0.4.1 utf8_1.2.4
[7] R6_2.5.1 lazyeval_0.2.2
[9] uwot_0.2.2 rhdf5filters_1.16.0
[11] withr_3.0.0 gridExtra_2.3
[13] progressr_0.14.0 cli_3.6.2
[15] formatR_1.14 spatstat.explore_3.2-7
[17] fastDummies_1.7.3 labeling_0.4.3
[19] spatstat.data_3.0-4 ggridges_0.5.6
[21] pbapply_1.7-2 parallelly_1.37.1
[23] limma_3.60.2 RSQLite_2.3.7
[25] generics_0.1.3 ica_1.0-3
[27] spatstat.random_3.2-3 dplyr_1.1.4
[29] ggbeeswarm_0.7.2 fansi_1.0.6
[31] lifecycle_1.0.4 yaml_2.3.8
[33] edgeR_4.2.0 BiocFileCache_2.12.0
[35] Rtsne_0.17 grid_4.4.1
[37] blob_1.2.4 promises_1.3.0
[39] dqrng_0.4.1 ExperimentHub_2.12.0
[41] crayon_1.5.2 dir.expiry_1.12.0
[43] miniUI_0.1.1.1 lattice_0.22-6
[45] beachmat_2.20.0 cowplot_1.1.3
[47] KEGGREST_1.44.0 magick_2.8.3
[49] pillar_1.9.0 knitr_1.47
[51] metapod_1.12.0 rjson_0.2.21
[53] future.apply_1.11.2 codetools_0.2-20
[55] leiden_0.4.3.1 glue_1.7.0
[57] data.table_1.15.4 vctrs_0.6.5
[59] png_0.1-8 spam_2.10-0
[61] gtable_0.3.5 cachem_1.1.0
[63] xfun_0.44 mime_0.12
[65] survival_3.6-4 statmod_1.5.0
[67] fitdistrplus_1.1-11 ROCR_1.0-11
[69] nlme_3.1-164 bit64_4.0.5
[71] filelock_1.0.3 RcppAnnoy_0.0.22
[73] BumpyMatrix_1.12.0 irlba_2.3.5.1
[75] vipor_0.4.7 KernSmooth_2.23-24
[77] colorspace_2.1-0 DBI_1.2.3
[79] tidyselect_1.2.1 bit_4.0.5
[81] compiler_4.4.1 curl_5.2.1
[83] basilisk.utils_1.16.0 plotly_4.10.4
[85] scales_1.3.0 lmtest_0.9-40
[87] rappdirs_0.3.3 stringr_1.5.1
[89] digest_0.6.35 goftest_1.2-3
[91] spatstat.utils_3.0-4 rmarkdown_2.27
[93] basilisk_1.16.0 XVector_0.44.0
[95] htmltools_0.5.8.1 pkgconfig_2.0.3
[97] sparseMatrixStats_1.16.0 highr_0.11
[99] dbplyr_2.5.0 fastmap_1.2.0
[101] rlang_1.1.3 htmlwidgets_1.6.4
[103] UCSC.utils_1.0.0 shiny_1.8.1.1
[105] DelayedMatrixStats_1.26.0 farver_2.1.2
[107] zoo_1.8-12 jsonlite_1.8.8
[109] magrittr_2.0.3 GenomeInfoDbData_1.2.12
[111] dotCall64_1.1-1 patchwork_1.2.0
[113] Rhdf5lib_1.26.0 munsell_0.5.1
[115] Rcpp_1.0.12 viridis_0.6.5
[117] reticulate_1.37.0 stringi_1.8.4
[119] zlibbioc_1.50.0 MASS_7.3-60.2
[121] AnnotationHub_3.12.0 plyr_1.8.9
[123] parallel_4.4.1 listenv_0.9.1
[125] ggrepel_0.9.5 deldir_2.0-4
[127] Biostrings_2.72.1 splines_4.4.1
[129] tensor_1.5 locfit_1.5-9.9
[131] igraph_2.0.3 spatstat.geom_3.2-9
[133] RcppHNSW_0.6.0 reshape2_1.4.4
[135] ScaledMatrix_1.12.0 BiocVersion_3.19.1
[137] evaluate_0.23 renv_1.0.11
[139] BiocManager_1.30.23 httpuv_1.6.15
[141] RANN_2.6.1 tidyr_1.3.1
[143] purrr_1.0.2 polyclip_1.10-6
[145] future_1.33.2 scattermore_1.2
[147] rsvd_1.0.5 xtable_1.8-4
[149] RSpectra_0.16-1 later_1.3.2
[151] viridisLite_0.4.2 tibble_3.2.1
[153] memoise_2.0.1 beeswarm_0.4.0
[155] AnnotationDbi_1.66.0 cluster_2.1.6
[157] globals_0.16.3 Content from Accessing data from the Human Cell Atlas (HCA)
Last updated on 2024-11-11 | Edit this page
Overview
Questions
- How to obtain single-cell reference maps from the Human Cell Atlas?
Objectives
- Learn about different resources for public single-cell RNA-seq data.
- Access data from the Human Cell Atlas using the
CuratedAtlasQueryRpackage. - Query for cells of interest and download them into a
SingleCellExperimentobject.
Single Cell data sources
HCA Project
The Human Cell Atlas (HCA) is a large project that aims to learn from and map every cell type in the human body. The project extracts spatial and molecular characteristics in order to understand cellular function and networks. It is an international collaborative that charts healthy cells in the human body at all ages. There are about 37.2 trillion cells in the human body. To read more about the project, head over to their website at https://www.humancellatlas.org.
CELLxGENE
CELLxGENE is a database and a suite of tools that help scientists to find, download, explore, analyze, annotate, and publish single cell data. It includes several analytic and visualization tools to help you to discover single cell data patterns. To see the list of tools, browse to https://cellxgene.cziscience.com/.
CELLxGENE | Census
The Census provides efficient computational tooling to access, query, and analyze all single-cell RNA data from CZ CELLxGENE Discover. Using a new access paradigm of cell-based slicing and querying, you can interact with the data through TileDB-SOMA, or get slices in AnnData or Seurat objects, thus accelerating your research by significantly minimizing data harmonization at https://chanzuckerberg.github.io/cellxgene-census/.
The CuratedAtlasQueryR Project
The CuratedAtlasQueryR is an alternative package that
can also be used to access the CELLxGENE data from R through a tidy API.
The data has also been harmonized, curated, and re-annotated across
studies.
CuratedAtlasQueryR supports data access and programmatic
exploration of the harmonized atlas. Cells of interest can be selected
based on ontology, tissue of origin, demographics, and disease. For
example, the user can select CD4 T helper cells across healthy and
diseased lymphoid tissue. The data for the selected cells can be
downloaded locally into SingleCellExperiment objects. Pseudo bulk counts
are also available to facilitate large-scale, summary analyses of
transcriptional profiles.

Data Sources in R / Bioconductor
There are a few options to access single cell data with R / Bioconductor.
| Package | Target | Description |
|---|---|---|
| hca | HCA Data Portal API | Project, Sample, and File level HCA data |
| cellxgenedp | CellxGene | Human and mouse SC data including HCA |
| CuratedAtlasQueryR | CellxGene | fine-grained query capable CELLxGENE data including HCA |
Installation
R
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("CuratedAtlasQueryR")
HCA Metadata
The metadata allows the user to get a lay of the land of what is available via the package. In this example, we are using the sample database URL which allows us to get a small and quick subset of the available metadata.
R
metadata <- get_metadata(remote_url = CuratedAtlasQueryR::SAMPLE_DATABASE_URL) |>
collect()
Get a view of the first 10 columns in the metadata with
glimpse()
R
metadata |>
select(1:10) |>
glimpse()
OUTPUT
Rows: ??
Columns: 10
Database: DuckDB v0.10.2 [unknown@Linux 6.5.0-1021-azure:R 4.4.0/:memory:]
$ cell_ <chr> "TTATGCTAGGGTGTTG_12", "GCTTGAACATGG…
$ sample_ <chr> "039c558ca1c43dc74c563b58fe0d6289", …
$ cell_type <chr> "mature NK T cell", "mature NK T cel…
$ cell_type_harmonised <chr> "immune_unclassified", "cd8 tem", "i…
$ confidence_class <dbl> 5, 3, 5, 5, 5, 5, 5, 5, 5, 5, 5, 1, …
$ cell_annotation_azimuth_l2 <chr> "gdt", "cd8 tem", "cd8 tem", "cd8 te…
$ cell_annotation_blueprint_singler <chr> "cd4 tem", "cd8 tem", "cd8 tcm", "cl…
$ cell_annotation_monaco_singler <chr> "natural killer", "effector memory c…
$ sample_id_db <chr> "0c1d320a7d0cbbc281a535912722d272", …
$ `_sample_name` <chr> "BPH340PrSF_Via___transition zone of…A tangent on the pipe operator
The vignette materials provided by CuratedAtlasQueryR
show the use of the ‘native’ R pipe (implemented after R version
4.1.0). For those not familiar with the pipe operator
(|>), it allows you to chain functions by passing the
left-hand side as the first argument to the function on the right-hand
side. It is used extensively in the tidyverse dialect of R,
especially within the dplyr package.
The pipe operator can be read as “and then”. Thankfully, R doesn’t care about whitespace, so it’s common to start a new line after a pipe. Together these points enable users to “chain” complex sequences of commands into readable blocks.
In this example, we start with the built-in mtcars
dataset and then filter to rows where cyl is not equal to
4, and then compute the mean disp value by each unique
cyl value.
R
mtcars |>
filter(cyl != 4) |>
summarise(avg_disp = mean(disp),
.by = cyl)
OUTPUT
cyl avg_disp
1 6 183.3143
2 8 353.1000This command is equivalent to the following:
R
summarise(filter(mtcars, cyl != 4), mean_disp = mean(disp), .by = cyl)
Exploring the metadata
Let’s examine the metadata to understand what information it contains.
We can tally the tissue types across datasets to see what tissues the experimental data come from:
R
metadata |>
distinct(tissue, dataset_id) |>
count(tissue) |>
arrange(-n)
OUTPUT
# A tibble: 33 × 2
tissue n
<chr> <int>
1 blood 17
2 kidney 8
3 cortex of kidney 7
4 heart left ventricle 7
5 renal medulla 6
6 respiratory airway 6
7 bone marrow 4
8 kidney blood vessel 4
9 lung 4
10 renal pelvis 4
# ℹ 23 more rowsWe can do the same for the assay types:
R
metadata |>
distinct(assay, dataset_id) |>
count(assay)
OUTPUT
# A tibble: 12 × 2
assay n
<chr> <int>
1 10x 3' v1 1
2 10x 3' v2 27
3 10x 3' v3 21
4 10x 5' v1 7
5 10x 5' v2 2
6 Drop-seq 1
7 Seq-Well 2
8 Slide-seq 4
9 Smart-seq2 1
10 Visium Spatial Gene Expression 7
11 scRNA-seq 4
12 sci-RNA-seq 1Challenge
Look through the full list of metadata column names. Do any other metadata columns jump out as interesting to you for your work?
R
names(metadata)
Downloading single cell data
The data can be provided as either “counts” or counts per million
“cpm” as given by the assays argument in the
get_single_cell_experiment() function. By default, the
SingleCellExperiment provided will contain only the
‘counts’ data.
For the sake of demonstration, we’ll focus this small subset of
samples. We use the filter() function from the
dplyr package to identify cells meeting the following
criteria:
- African ethnicity
- 10x assay
- lung parenchyma tissue
- CD4 cells
R
sample_subset <- metadata |>
filter(
ethnicity == "African" &
grepl("10x", assay) &
tissue == "lung parenchyma" &
grepl("CD4", cell_type)
)
Out of the 111355 cells in the sample database, 1571 cells meet this criteria.
Now we can use get_single_cell_experiment():
R
single_cell_counts <- sample_subset |>
get_single_cell_experiment()
single_cell_counts
OUTPUT
class: SingleCellExperiment
dim: 36229 1571
metadata(0):
assays(1): counts
rownames(36229): A1BG A1BG-AS1 ... ZZEF1 ZZZ3
rowData names(0):
colnames(1571): ACACCAAAGCCACCTG_SC18_1 TCAGCTCCAGACAAGC_SC18_1 ...
CAGCATAAGCTAACAA_F02607_1 AAGGAGCGTATAATGG_F02607_1
colData names(56): sample_ cell_type ... updated_at_y original_cell_id
reducedDimNames(0):
mainExpName: NULL
altExpNames(0):You can provide different arguments to
get_single_cell_experiment() to get different formats or
subsets of the data, like data scaled to counts per million:
R
sample_subset |>
get_single_cell_experiment(assays = "cpm")
OUTPUT
class: SingleCellExperiment
dim: 36229 1571
metadata(0):
assays(1): cpm
rownames(36229): A1BG A1BG-AS1 ... ZZEF1 ZZZ3
rowData names(0):
colnames(1571): ACACCAAAGCCACCTG_SC18_1 TCAGCTCCAGACAAGC_SC18_1 ...
CAGCATAAGCTAACAA_F02607_1 AAGGAGCGTATAATGG_F02607_1
colData names(56): sample_ cell_type ... updated_at_y original_cell_id
reducedDimNames(0):
mainExpName: NULL
altExpNames(0):or data on only specific genes:
R
single_cell_counts <- sample_subset |>
get_single_cell_experiment(assays = "cpm", features = "PUM1")
single_cell_counts
OUTPUT
class: SingleCellExperiment
dim: 1 1571
metadata(0):
assays(1): cpm
rownames(1): PUM1
rowData names(0):
colnames(1571): ACACCAAAGCCACCTG_SC18_1 TCAGCTCCAGACAAGC_SC18_1 ...
CAGCATAAGCTAACAA_F02607_1 AAGGAGCGTATAATGG_F02607_1
colData names(56): sample_ cell_type ... updated_at_y original_cell_id
reducedDimNames(0):
mainExpName: NULL
altExpNames(0):Or if needed, the H5 SingleCellExperiment can be
returned a Seurat object (note that this may take a long time and use a
lot of memory depending on how many cells you are requesting).
R
single_cell_counts <- sample_subset |>
get_seurat()
single_cell_counts
Save your SingleCellExperiment
Once you have a dataset you’re happy with, you’ll probably want to
save it. The recommended way of saving these
SingleCellExperiment objects is to use
saveHDF5SummarizedExperiment from the
HDF5Array package.
R
single_cell_counts |> saveHDF5SummarizedExperiment("single_cell_counts")
Exercises
Exercise 1: Basic counting + piping
Use count and arrange to get the number of
cells per tissue in descending order.
R
metadata |>
count(tissue) |>
arrange(-n)
OUTPUT
# A tibble: 33 × 2
tissue n
<chr> <int>
1 cortex of kidney 36940
2 kidney 23549
3 lung parenchyma 16719
4 renal medulla 7729
5 respiratory airway 7153
6 blood 4248
7 bone marrow 4113
8 heart left ventricle 1454
9 transition zone of prostate 1140
10 lung 1137
# ℹ 23 more rowsExercise 2: Tissue & type counting
count() can group by multiple factors by simply adding
another grouping column as an additional argument. Get a tally of the
highest number of cell types per tissue combination. What tissue has the
most numerous type of cells?
R
metadata |>
count(tissue, cell_type) |>
arrange(-n) |>
head(n = 1)
OUTPUT
# A tibble: 1 × 3
tissue cell_type n
<chr> <chr> <int>
1 cortex of kidney epithelial cell of proximal tubule 29986Exercise 3: Comparing metadata categories
Spot some differences between the tissue and
tissue_harmonised columns. Use count to
summarise.
R
metadata |>
count(tissue) |>
arrange(-n)
OUTPUT
# A tibble: 33 × 2
tissue n
<chr> <int>
1 cortex of kidney 36940
2 kidney 23549
3 lung parenchyma 16719
4 renal medulla 7729
5 respiratory airway 7153
6 blood 4248
7 bone marrow 4113
8 heart left ventricle 1454
9 transition zone of prostate 1140
10 lung 1137
# ℹ 23 more rowsR
metadata |>
count(tissue_harmonised) |>
arrange(-n)
OUTPUT
# A tibble: 19 × 2
tissue_harmonised n
<chr> <int>
1 kidney 68851
2 lung 25737
3 blood 4248
4 bone 4113
5 heart 1454
6 lymph node 1210
7 prostate 1156
8 intestine large 816
9 liver 793
10 thymus 753
11 intestine small 530
12 eye 437
13 intestine 360
14 esophagus 334
15 nose 290
16 vasculature 143
17 brain 97
18 adrenal gland 20
19 axilla 13For example you can see that tissue_harmonised merges
the cortex of kidney and kidney groups in
tissue.
To see the full list of curated columns in the metadata, see the
Details section in the ?get_metadata documentation
page.
Exercise 4: Highly specific cell groups
Now that we are a little familiar with navigating the metadata, let’s
obtain a SingleCellExperiment of 10X scRNA-seq counts of
cd8 tem lung cells for females older than
80 with COVID-19. Note: Use the harmonized
columns, where possible.
R
metadata |>
filter(
sex == "female" &
age_days > 80 * 365 &
grepl("10x", assay) &
disease == "COVID-19" &
tissue_harmonised == "lung" &
cell_type_harmonised == "cd8 tem"
) |>
get_single_cell_experiment()
OUTPUT
class: SingleCellExperiment
dim: 36229 12
metadata(0):
assays(1): counts
rownames(36229): A1BG A1BG-AS1 ... ZZEF1 ZZZ3
rowData names(0):
colnames(12): TCATCATCATAACCCA_1 TATCTGTCAGAACCGA_1 ...
CCCTTAGCATGACTTG_1 CAGTTCCGTAGCGTAG_1
colData names(56): sample_ cell_type ... updated_at_y original_cell_id
reducedDimNames(0):
mainExpName: NULL
altExpNames(0):You can see we don’t get very many cells given the strict set of conditions we used.
Key Points
- The
CuratedAtlasQueryRpackage provides programmatic access to single-cell reference maps from the Human Cell Atlas. - The package provides functionality to query for cells of interest
and to download them into a
SingleCellExperimentobject.
Session Info
R
sessionInfo()
OUTPUT
R version 4.4.1 (2024-06-14)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 22.04.5 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.10.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.10.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
time zone: UTC
tzcode source: system (glibc)
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] dplyr_1.1.4 CuratedAtlasQueryR_1.2.0
[3] scDblFinder_1.18.0 scran_1.32.0
[5] scater_1.32.0 ggplot2_3.5.1
[7] scuttle_1.14.0 EnsDb.Mmusculus.v79_2.99.0
[9] ensembldb_2.28.0 AnnotationFilter_1.28.0
[11] GenomicFeatures_1.56.0 AnnotationDbi_1.66.0
[13] DropletUtils_1.24.0 MouseGastrulationData_1.18.0
[15] SpatialExperiment_1.14.0 SingleCellExperiment_1.26.0
[17] SummarizedExperiment_1.34.0 Biobase_2.64.0
[19] GenomicRanges_1.56.0 GenomeInfoDb_1.40.1
[21] IRanges_2.38.0 S4Vectors_0.42.0
[23] BiocGenerics_0.50.0 MatrixGenerics_1.16.0
[25] matrixStats_1.3.0 BiocStyle_2.32.0
loaded via a namespace (and not attached):
[1] spatstat.sparse_3.0-3 ProtGenerics_1.36.0
[3] bitops_1.0-7 httr_1.4.7
[5] RColorBrewer_1.1-3 tools_4.4.1
[7] sctransform_0.4.1 utf8_1.2.4
[9] R6_2.5.1 HDF5Array_1.32.0
[11] uwot_0.2.2 lazyeval_0.2.2
[13] rhdf5filters_1.16.0 withr_3.0.0
[15] sp_2.1-4 gridExtra_2.3
[17] progressr_0.14.0 cli_3.6.2
[19] formatR_1.14 spatstat.explore_3.2-7
[21] fastDummies_1.7.3 Seurat_5.1.0
[23] spatstat.data_3.0-4 ggridges_0.5.6
[25] pbapply_1.7-2 Rsamtools_2.20.0
[27] R.utils_2.12.3 parallelly_1.37.1
[29] limma_3.60.2 RSQLite_2.3.7
[31] generics_0.1.3 BiocIO_1.14.0
[33] spatstat.random_3.2-3 ica_1.0-3
[35] Matrix_1.7-0 ggbeeswarm_0.7.2
[37] fansi_1.0.6 abind_1.4-5
[39] R.methodsS3_1.8.2 lifecycle_1.0.4
[41] yaml_2.3.8 edgeR_4.2.0
[43] rhdf5_2.48.0 SparseArray_1.4.8
[45] BiocFileCache_2.12.0 Rtsne_0.17
[47] grid_4.4.1 blob_1.2.4
[49] promises_1.3.0 dqrng_0.4.1
[51] ExperimentHub_2.12.0 crayon_1.5.2
[53] miniUI_0.1.1.1 lattice_0.22-6
[55] beachmat_2.20.0 cowplot_1.1.3
[57] KEGGREST_1.44.0 magick_2.8.3
[59] pillar_1.9.0 knitr_1.47
[61] metapod_1.12.0 rjson_0.2.21
[63] xgboost_1.7.7.1 future.apply_1.11.2
[65] codetools_0.2-20 leiden_0.4.3.1
[67] glue_1.7.0 data.table_1.15.4
[69] vctrs_0.6.5 png_0.1-8
[71] spam_2.10-0 gtable_0.3.5
[73] assertthat_0.2.1 cachem_1.1.0
[75] xfun_0.44 S4Arrays_1.4.1
[77] mime_0.12 survival_3.6-4
[79] statmod_1.5.0 bluster_1.14.0
[81] fitdistrplus_1.1-11 ROCR_1.0-11
[83] nlme_3.1-164 bit64_4.0.5
[85] filelock_1.0.3 RcppAnnoy_0.0.22
[87] BumpyMatrix_1.12.0 irlba_2.3.5.1
[89] vipor_0.4.7 KernSmooth_2.23-24
[91] colorspace_2.1-0 DBI_1.2.3
[93] duckdb_0.10.2 tidyselect_1.2.1
[95] bit_4.0.5 compiler_4.4.1
[97] curl_5.2.1 BiocNeighbors_1.22.0
[99] DelayedArray_0.30.1 plotly_4.10.4
[101] rtracklayer_1.64.0 scales_1.3.0
[103] lmtest_0.9-40 rappdirs_0.3.3
[105] goftest_1.2-3 stringr_1.5.1
[107] digest_0.6.35 spatstat.utils_3.0-4
[109] rmarkdown_2.27 XVector_0.44.0
[111] htmltools_0.5.8.1 pkgconfig_2.0.3
[113] sparseMatrixStats_1.16.0 highr_0.11
[115] dbplyr_2.5.0 fastmap_1.2.0
[117] rlang_1.1.3 htmlwidgets_1.6.4
[119] UCSC.utils_1.0.0 shiny_1.8.1.1
[121] DelayedMatrixStats_1.26.0 zoo_1.8-12
[123] jsonlite_1.8.8 BiocParallel_1.38.0
[125] R.oo_1.26.0 BiocSingular_1.20.0
[127] RCurl_1.98-1.14 magrittr_2.0.3
[129] GenomeInfoDbData_1.2.12 dotCall64_1.1-1
[131] patchwork_1.2.0 Rhdf5lib_1.26.0
[133] munsell_0.5.1 Rcpp_1.0.12
[135] viridis_0.6.5 reticulate_1.37.0
[137] stringi_1.8.4 zlibbioc_1.50.0
[139] MASS_7.3-60.2 AnnotationHub_3.12.0
[141] plyr_1.8.9 parallel_4.4.1
[143] listenv_0.9.1 ggrepel_0.9.5
[145] deldir_2.0-4 Biostrings_2.72.1
[147] splines_4.4.1 tensor_1.5
[149] locfit_1.5-9.9 igraph_2.0.3
[151] spatstat.geom_3.2-9 RcppHNSW_0.6.0
[153] reshape2_1.4.4 ScaledMatrix_1.12.0
[155] BiocVersion_3.19.1 XML_3.99-0.16.1
[157] evaluate_0.23 SeuratObject_5.0.2
[159] renv_1.0.11 BiocManager_1.30.23
[161] httpuv_1.6.15 polyclip_1.10-6
[163] RANN_2.6.1 tidyr_1.3.1
[165] purrr_1.0.2 future_1.33.2
[167] scattermore_1.2 rsvd_1.0.5
[169] xtable_1.8-4 restfulr_0.0.15
[171] RSpectra_0.16-1 later_1.3.2
[173] viridisLite_0.4.2 tibble_3.2.1
[175] memoise_2.0.1 beeswarm_0.4.0
[177] GenomicAlignments_1.40.0 cluster_2.1.6
[179] globals_0.16.3