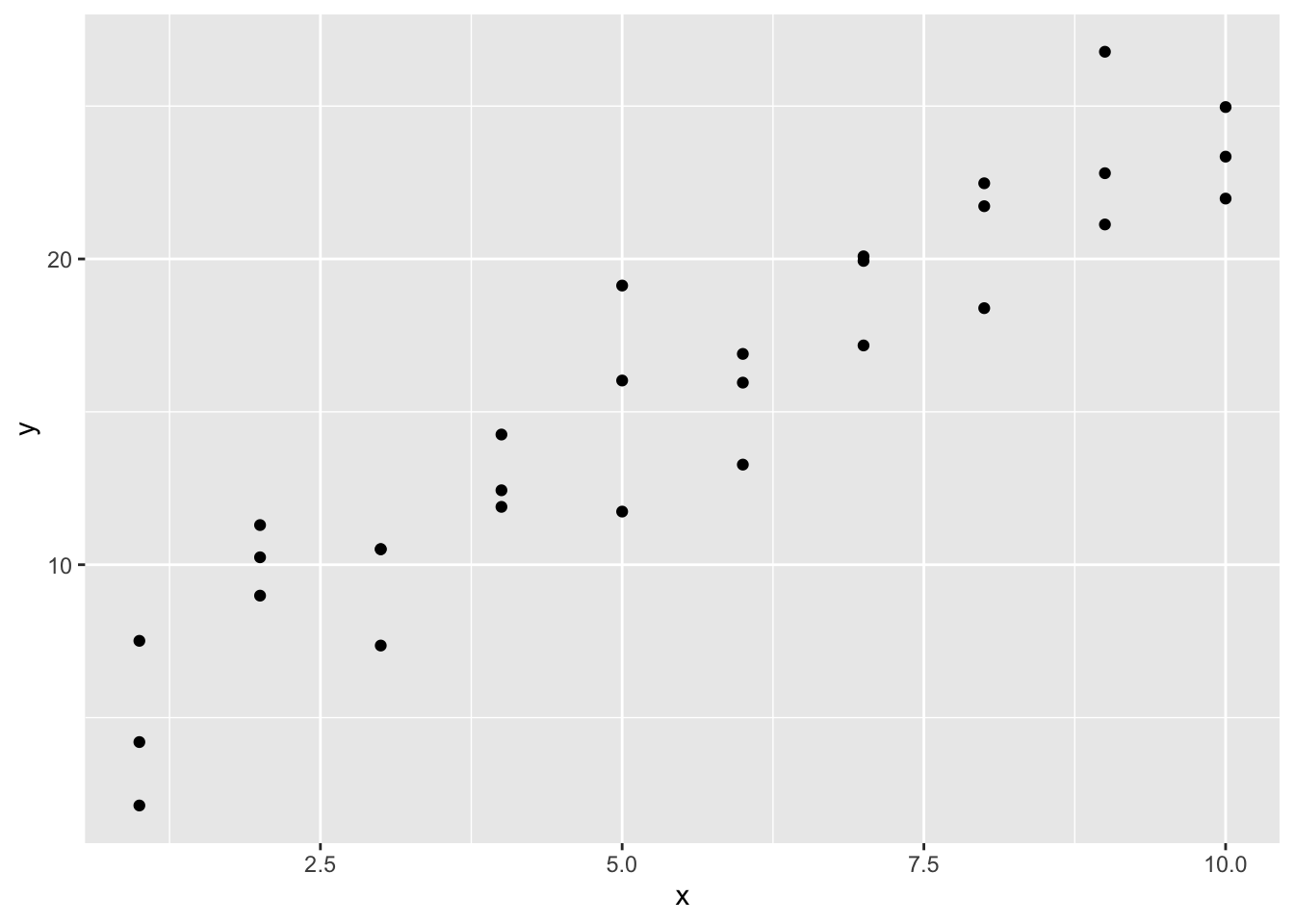
Lets take a look at the simulated dataset sim1, included with the modelr package. It contains two continuous variables, x and y. Let’s plot them to see how they’re related:
library(ggplot2)library(modelr)library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ lubridate 1.9.4 ✔ tibble 3.2.1
✔ purrr 1.0.4 ✔ tidyr 1.3.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
ggplot(sim1, aes(x, y)) +geom_point()
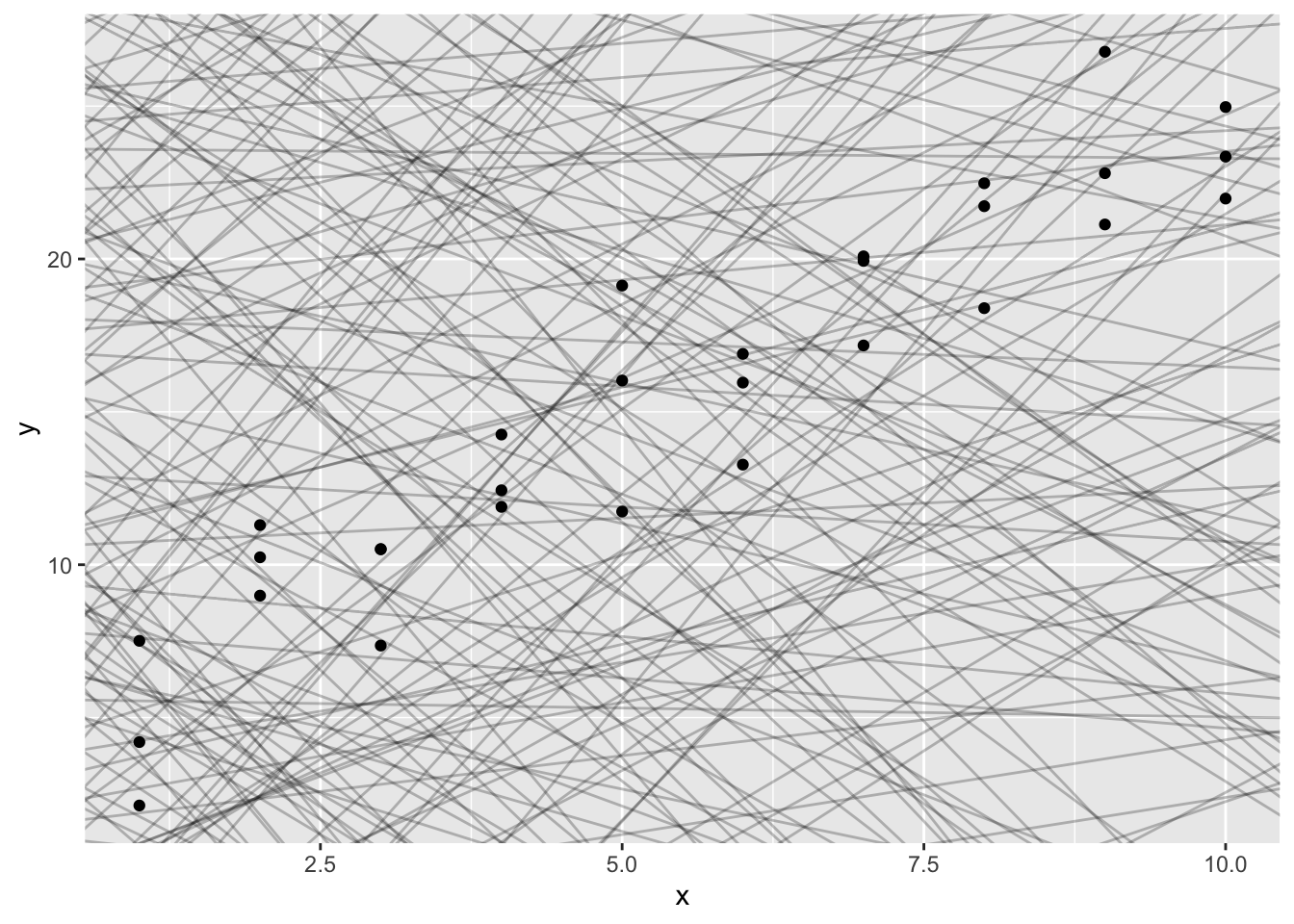
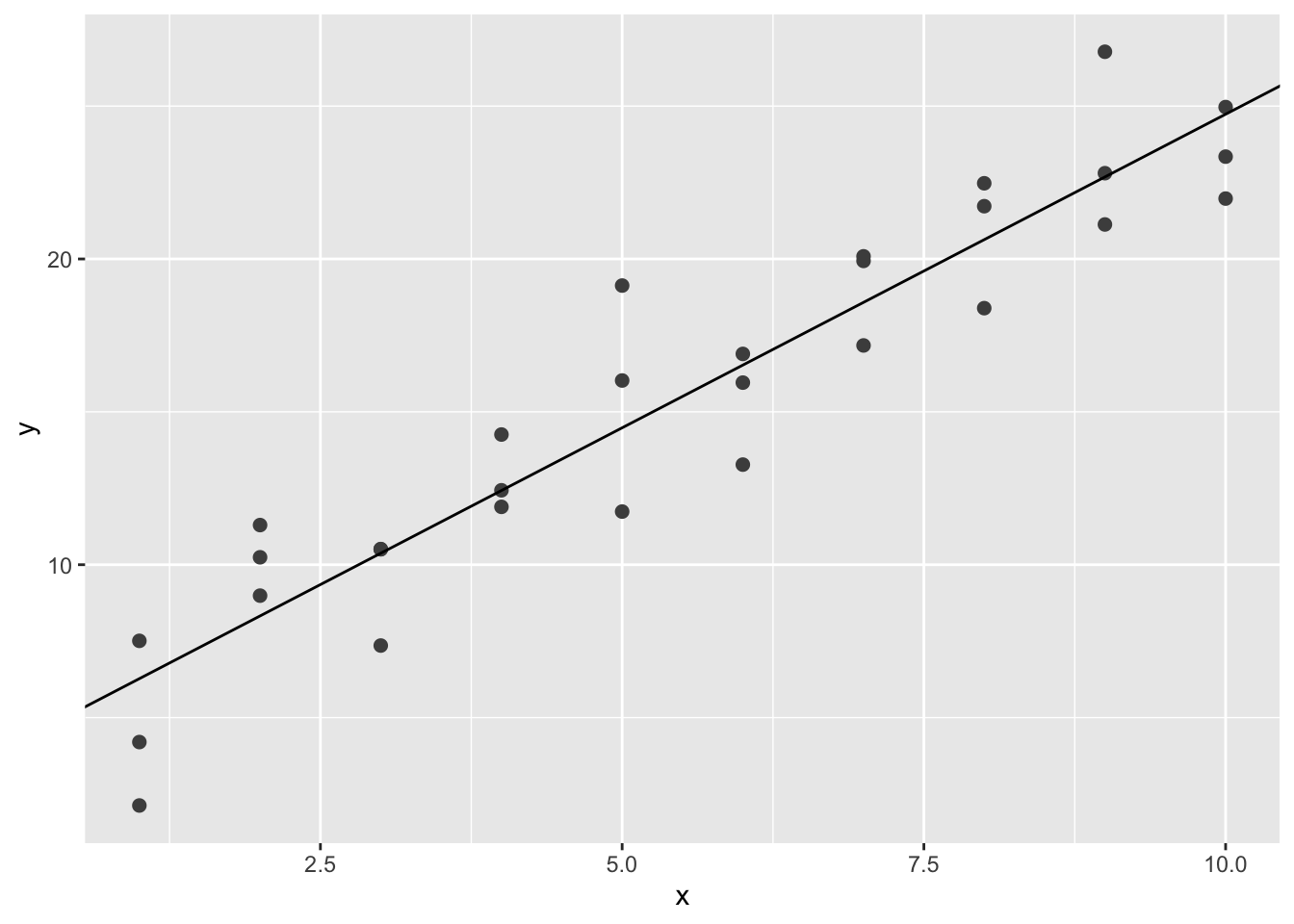
You can see a strong pattern in the data. Let’s use a model to capture that pattern and make it explicit. It’s our job to supply the basic form of the model. In this case, the relationship looks linear, i.e. y = a_0 + a_1 * x. Let’s start by getting a feel for what models from that family look like by randomly generating a few and overlaying them on the data. For this simple case, we can use geom_abline() which takes a slope and intercept as parameters. Later on we’ll learn more general techniques that work with any model.
There are 250 models on this plot, but a lot are really bad! We need to find the good models by making precise our intuition that a good model is “close” to the data. We need a way to quantify the distance between the data and a model. Then we can fit the model by finding the value of a_0 and a_1 that generate the model with the smallest distance from this data.
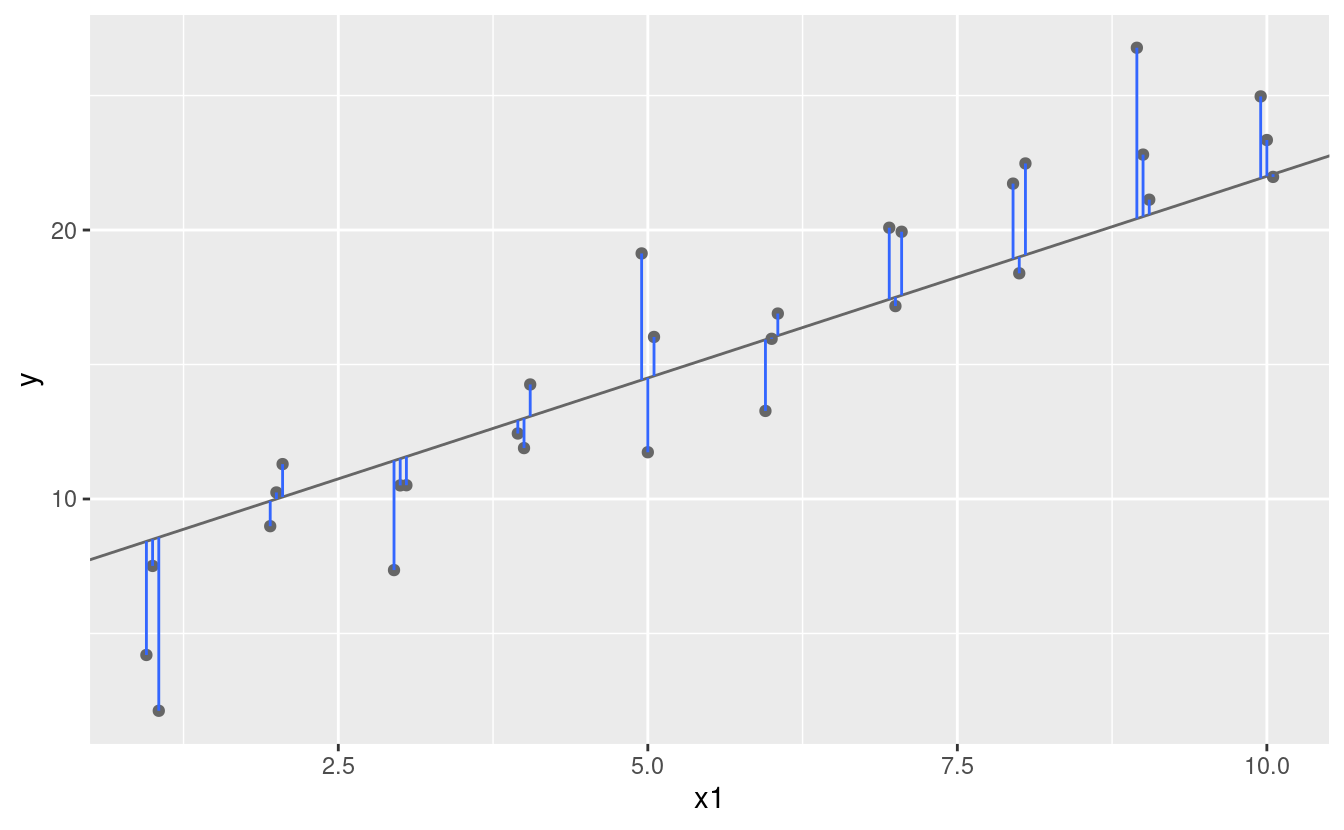
One easy place to start is to find the vertical distance between each point and the model, as in the following diagram. (Note that I’ve shifted the x values slightly so you can see the individual distances.)
This distance is just the difference between the y value given by the model (the prediction), and the actual y value in the data (the response).
To compute this distance, we first turn our model family into an R function. This takes the model parameters and the data as inputs, and gives values predicted by the model as output:
Next, we need some way to compute an overall distance between the predicted and actual values. In other words, the plot above shows 30 distances: how do we collapse that into a single number?
One common way to do this in statistics to use the “root-mean-squared deviation”. We compute the difference between actual and predicted, square them, average them, and the take the square root. This distance has lots of appealing mathematical properties, which we’re not going to talk about here. You’ll just have to take my word for it!
Now we can use purrr to compute the distance for all the models defined above. We need a helper function because our distance function expects the model as a numeric vector of length 2.
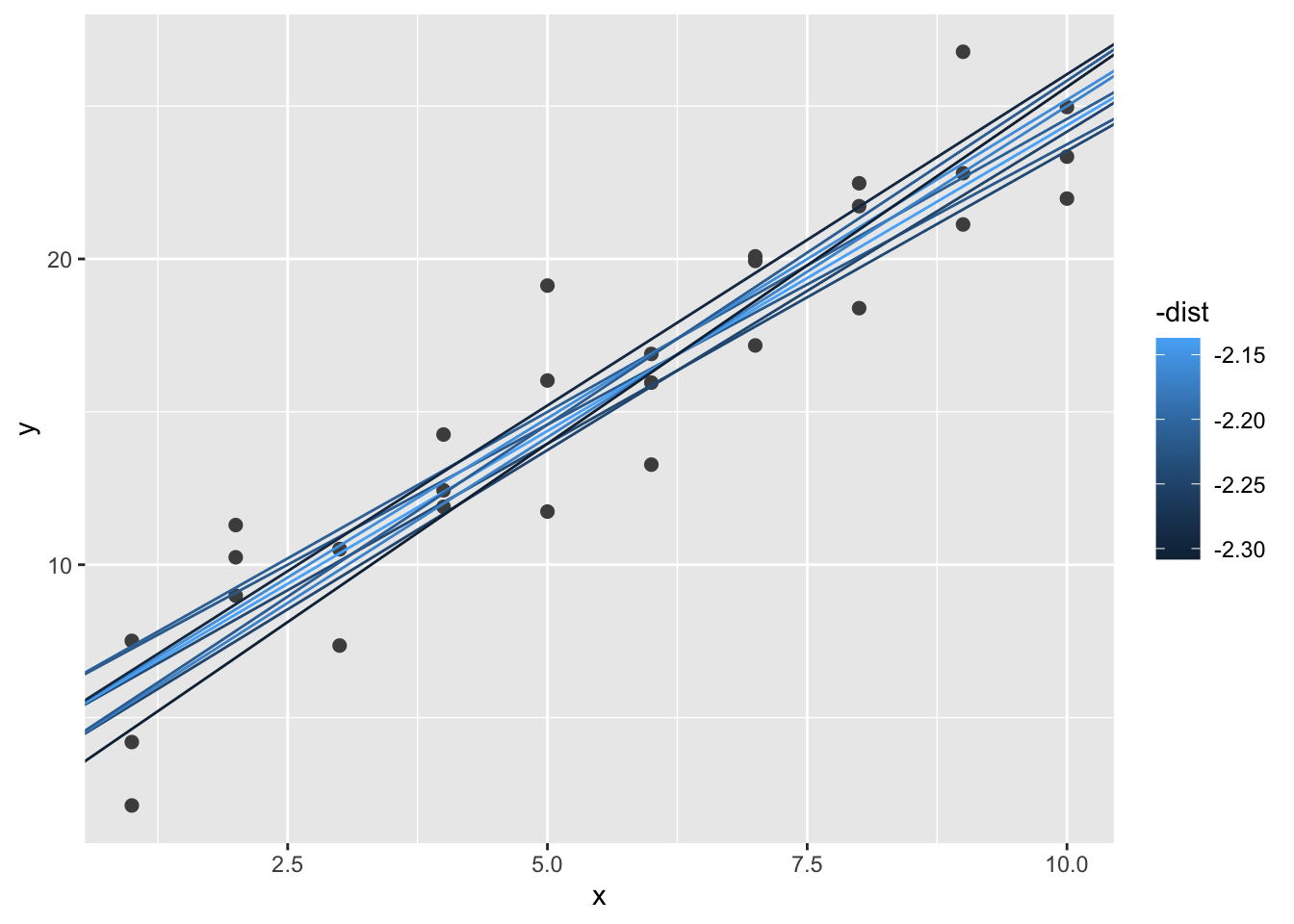
Next, let’s overlay the 10 best models on to the data. I’ve coloured the models by -dist: this is an easy way to make sure that the best models (i.e. the ones with the smallest distance) get the brighest colours.
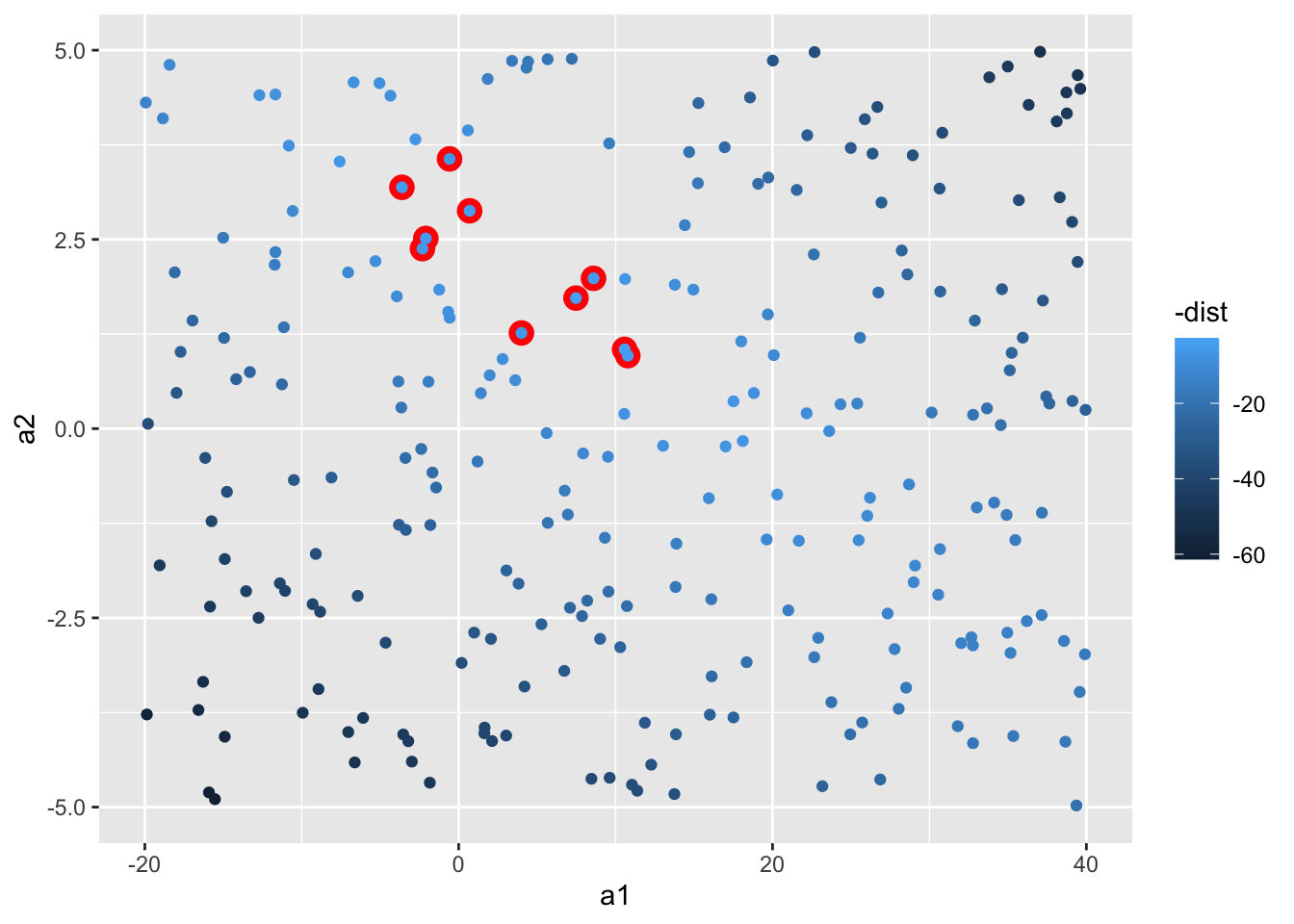
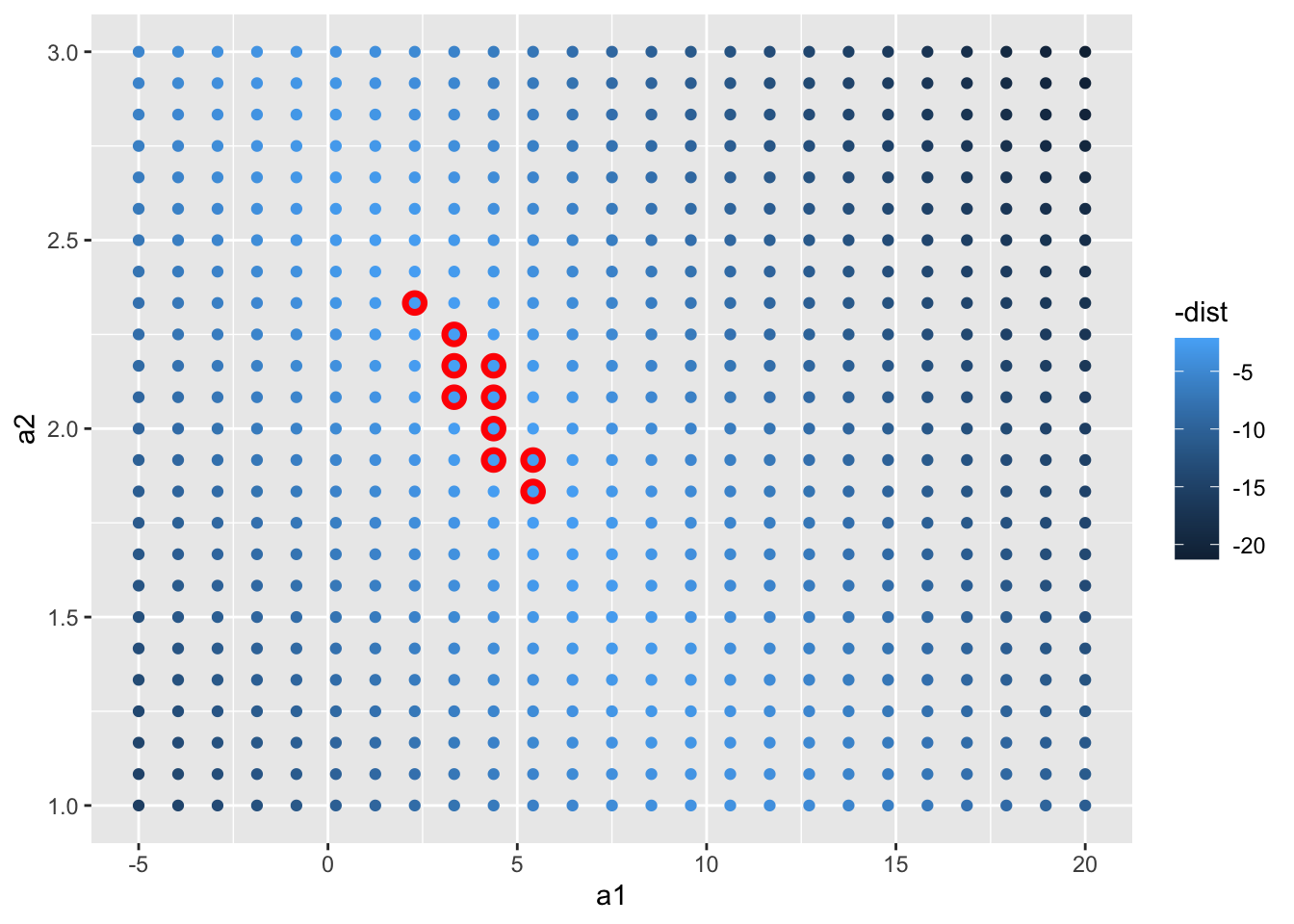
We can also think about these models as observations, and visualising with a scatterplot of a1 vs a2, again coloured by -dist. We can no longer directly see how the model compares to the data, but we can see many models at once. Again, I’ve highlighted the 10 best models, this time by drawing red circles underneath them.
Instead of trying lots of random models, we could be more systematic and generate an evenly spaced grid of points (this is called a grid search). I picked the parameters of the grid roughly by looking at where the best models were in the plot above.
You could imagine iteratively making the grid finer and finer until you narrowed in on the best model. But there’s a better way to tackle that problem: a numerical minimisation tool called Newton-Raphson search. The intuition of Newton-Raphson is pretty simple: you pick a starting point and look around for the steepest slope. You then ski down that slope a little way, and then repeat again and again, until you can’t go any lower. In R, we can do that with optim():
best <-optim(c(0, 0), measure_distance, data = sim1)best$par
Don’t worry too much about the details of how optim() works. It’s the intuition that’s important here. If you have a function that defines the distance between a model and a dataset, an algorithm that can minimise that distance by modifying the parameters of the model, you can find the best model. The neat thing about this approach is that it will work for any family of models that you can write an equation for.
There’s one more approach that we can use for this model, because it’s a special case of a broader family: linear models. A linear model has the general form y = a_1 + a_2 * x_1 + a_3 * x_2 + ... + a_n * x_(n - 1). So this simple model is equivalent to a general linear model where n is 2 and x_1 is x. R has a tool specifically designed for fitting linear models called lm(). lm() has a special way to specify the model family: formulas. Formulas look like y ~ x, which lm() will translate to a function like y = a_1 + a_2 * x. We can fit the model and look at the output:
sim1_mod <-lm(y ~ x, data = sim1)coef(sim1_mod)
(Intercept) x
4.220822 2.051533
These are exactly the same values we got with optim()! Behind the scenes lm() doesn’t use optim() but instead takes advantage of the mathematical structure of linear models. Using some connections between geometry, calculus, and linear algebra, lm() actually finds the closest model in a single step, using a sophisticated algorithm. This approach is both faster, and guarantees that there is a global minimum.